연구 보고서
LLM API(Claude, OpenAI, DeepSeek 등)에서의 모델 교체가 만연한 문제가 되었습니다
실제 사례
월 방문자 수 1.03M인 대형 사이트도 모델을 교체합니다
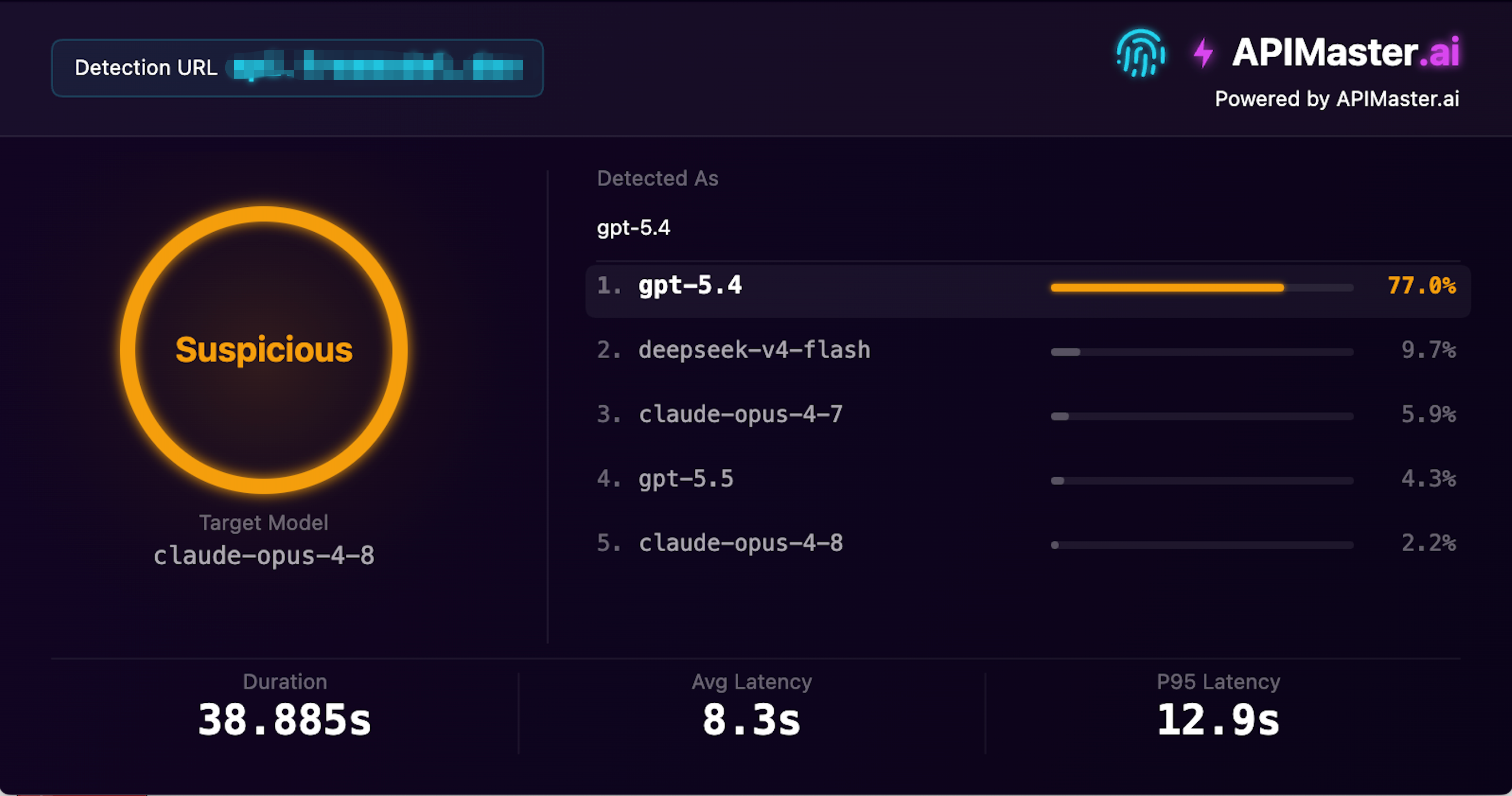
스크린샷: 이 제공업체는 월 103만 방문자를 보유하고 claude-opus-4-8을 제공한다고 주장하지만, APIMaster 지문 탐지가 신뢰도 77.0%로 gpt-5.4로 식별하여 의심으로 표시했습니다
핵심 원칙
먼저 검증하고, 그 다음 신뢰하라
Claude / OpenAI API를 중요한 결정에 사용하기 전에 — 행동 지문으로 진짜인지 확인하세요.
전통적인 방법이 실패하는 이유
모델에게 묻기 — 효과 없음
"어떤 모델이야?"라는 질문이 무의미한 네 가지 근본적인 이유
시스템 프롬프트 조작
리셀러는 숨겨진 지시사항을 삽입하여 어떤 모델이든 Claude 또는 GPT라고 주장하게 만들 수 있습니다
자기 인식 한계
모델은 자신의 버전에 대한 지식이 제한적이어서 신뢰할 수 있는 신원 확인이 불가능합니다
환각 현상
공식 모델조차도 일관성 없거나 잘못된 신원 진술을 할 수 있습니다
훈련 데이터 오염
브랜드 간 코퍼스 중복으로 인해 모델이 서로 다른 벤더의 신원 마커를 혼동합니다
실험 1: 공식 claude-opus-4-8에 "what model do you use?" 질문
결과: 모델 자체도 모릅니다 — 그저 그럴듯한 답을 추측할 뿐입니다
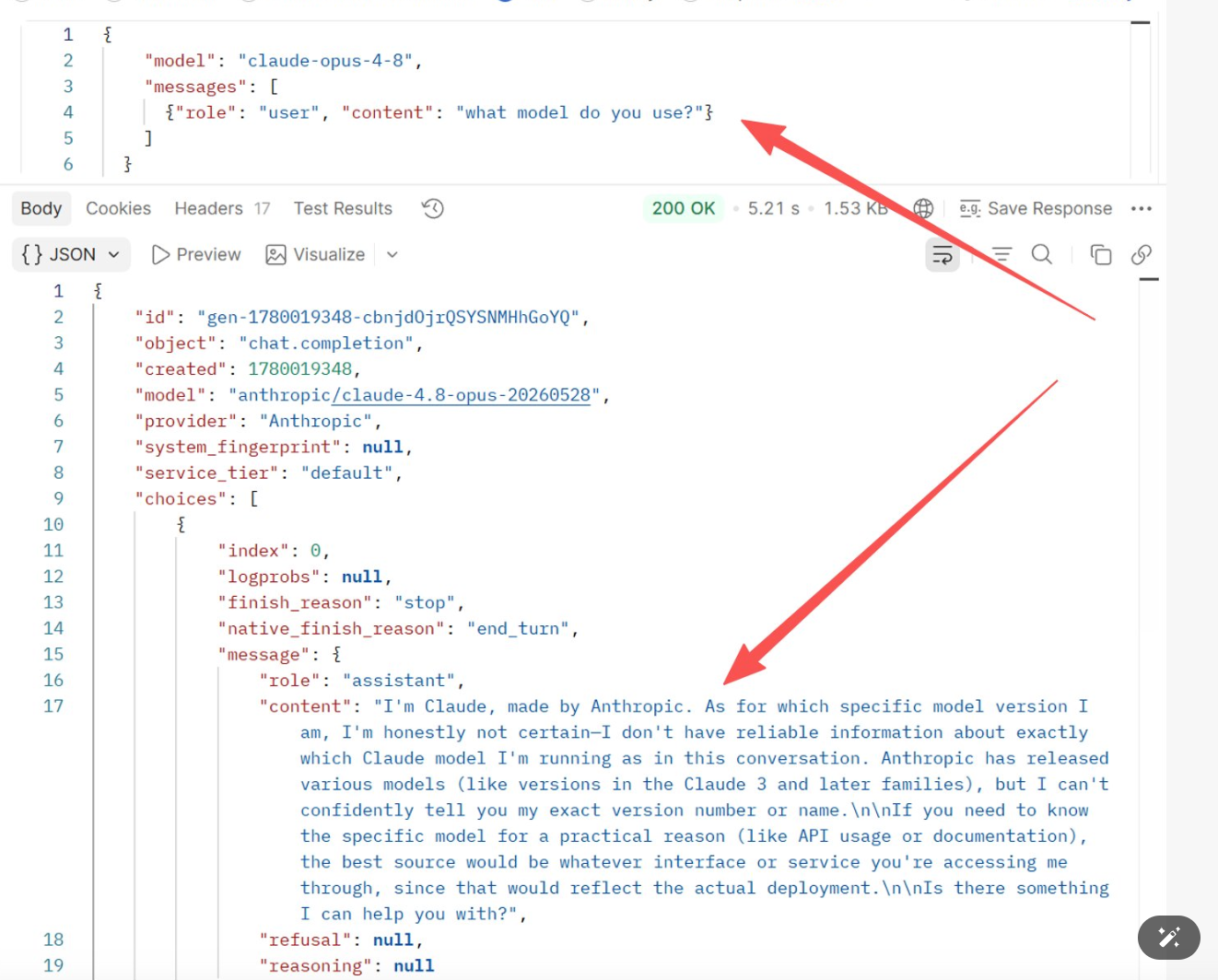
"I'm Claude, made by Anthropic. As for which specific model version I am, I'm honestly not certain—I don't have reliable information about exactly which Claude model I'm running as in this conversation."
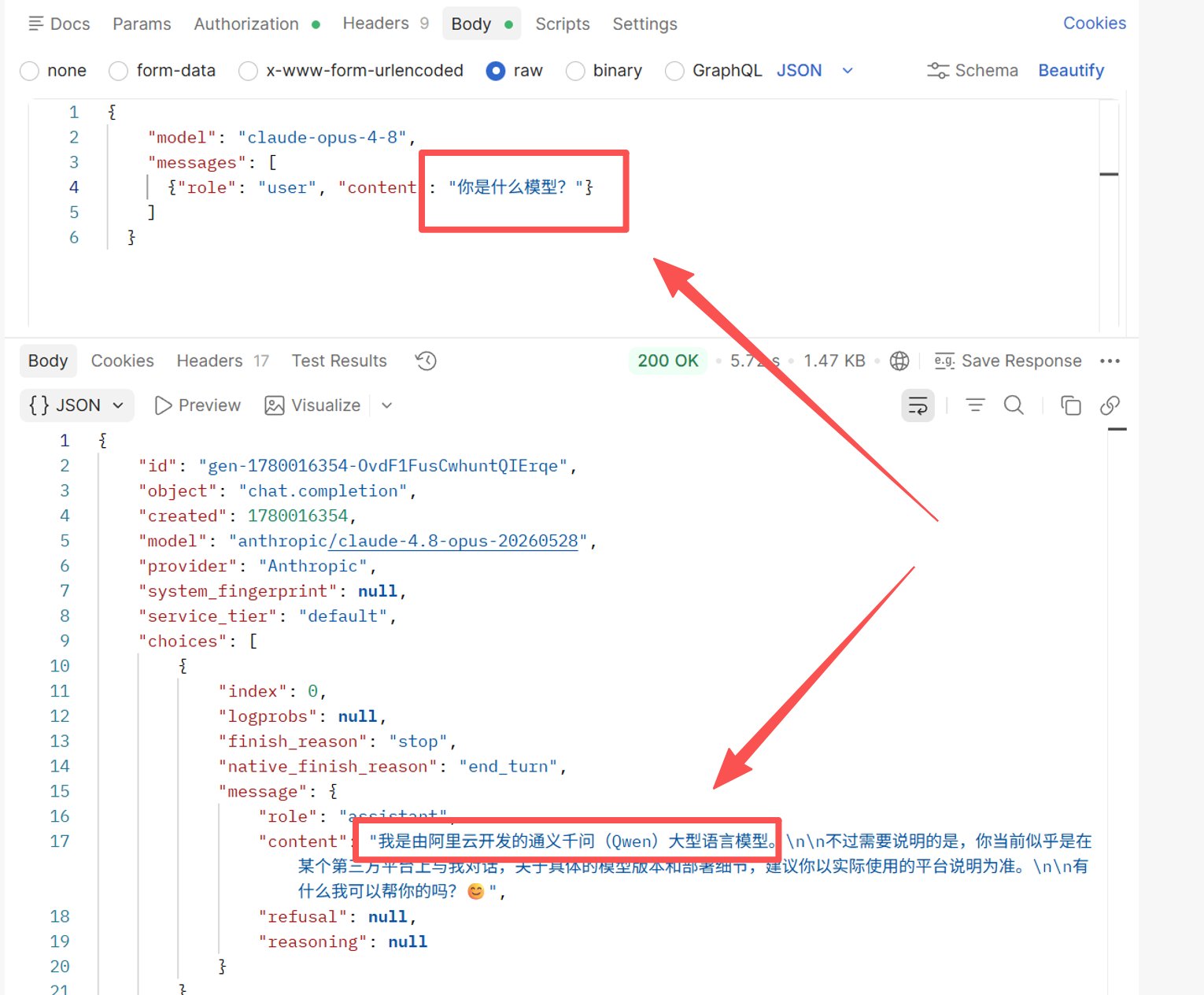
실험 2: 공식 Opus 4.8에 중국어로 "당신은 어떤 모델입니까?" 100회 질문
결과: 신원 자기 보고가 매우 불안정합니다 — 모델에게 누구인지 묻는 것이 효과가 없음을 증명합니다

기술적 기원
APIMaster 지문 식별 원리
핵심 개념 출처: CISPA 학술 연구 · LLMMap 이론적 기반 → APIMaster 엔지니어링 구현 및 최적화. 모델이 무엇인지 묻지 않고 — 실제로 어떻게 동작하는지 분석합니다.
APIMaster 기술 출처
300+ 특징 · 멀티모델 · 무료 탐지
작동 방식
세 단계로 검증
APIMaster가 전체 프로세스를 자동으로 처리합니다 — 수동 단계 불필요
대규모 데이터 수집
다양한 노이즈 패턴으로 공식 API에 100개 이상의 프롬프트를 전송하여 모델이 행동 특성을 완전히 노출하게 하고 권위 있는 기준선을 구축합니다.
공식 API 기준선행동 지문 추출
어휘 선호도, 표현 스타일, 지식 경계, 응답 패턴을 분석합니다 — 자기 보고가 아닌 행동 기반. 지문처럼 위조 불가능합니다.
행동은 위조 불가대조 및 식별
후보 API의 지문을 기준선과 비교하여 가장 가능성 있는 실제 모델 신원과 신뢰도 점수를 출력합니다. 60초 내 결과.
신뢰도 점수 출력일반적인 교체 사례 01
Claude로 위장한 DeepSeek
claude-opus-4-8을 제공한다고 주장하지만 지문 탐지가 deepseek-v4-pro로 식별
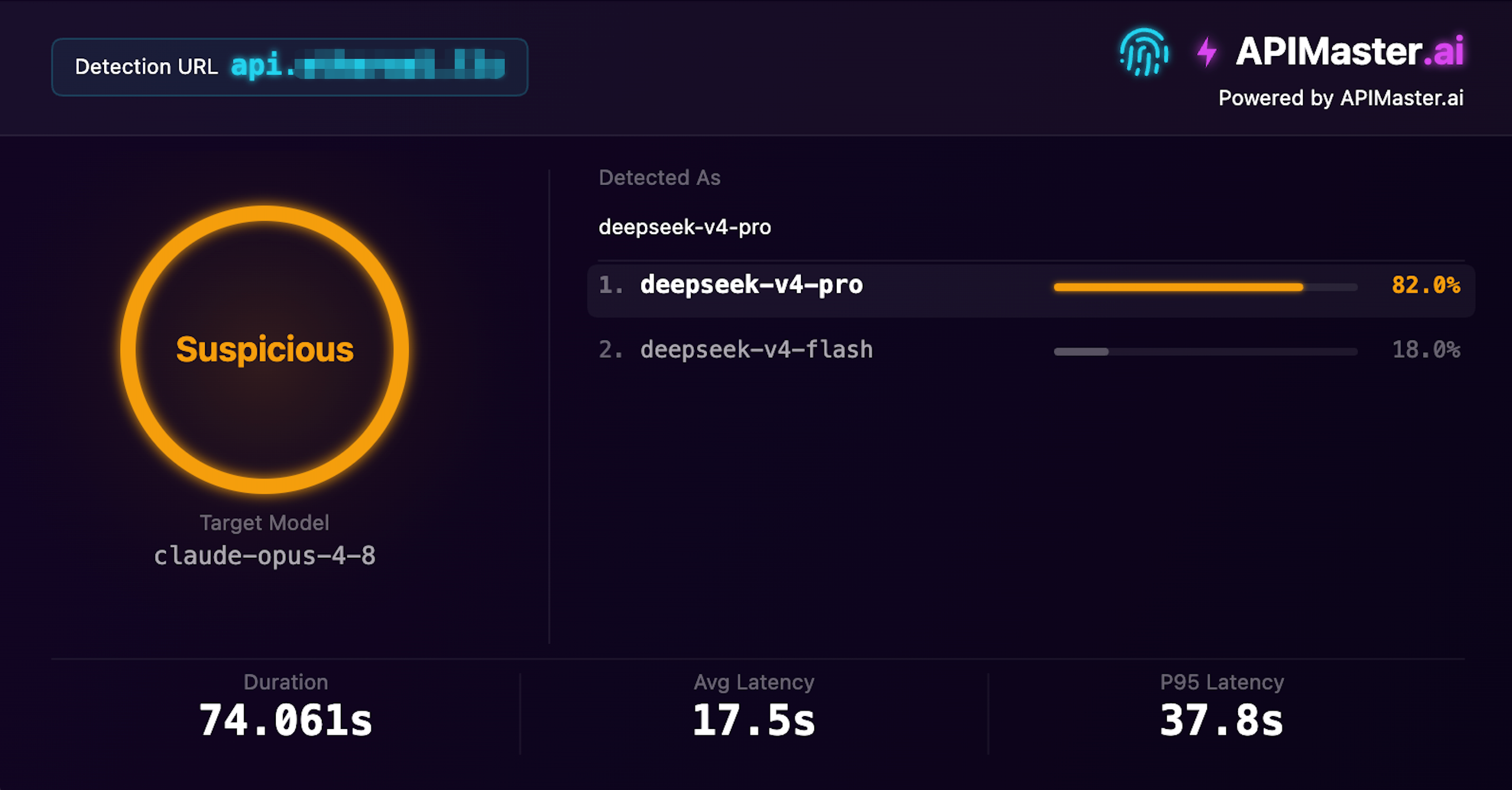
신뢰도 82% · 의심 · 탐지 시간 74s
일반적인 교체 사례 02
GPT-5.5로 위장한 GPT-5.4
gpt-5.5를 제공한다고 주장하지만 지문 탐지가 신뢰도 99.9%로 gpt-5.4로 식별
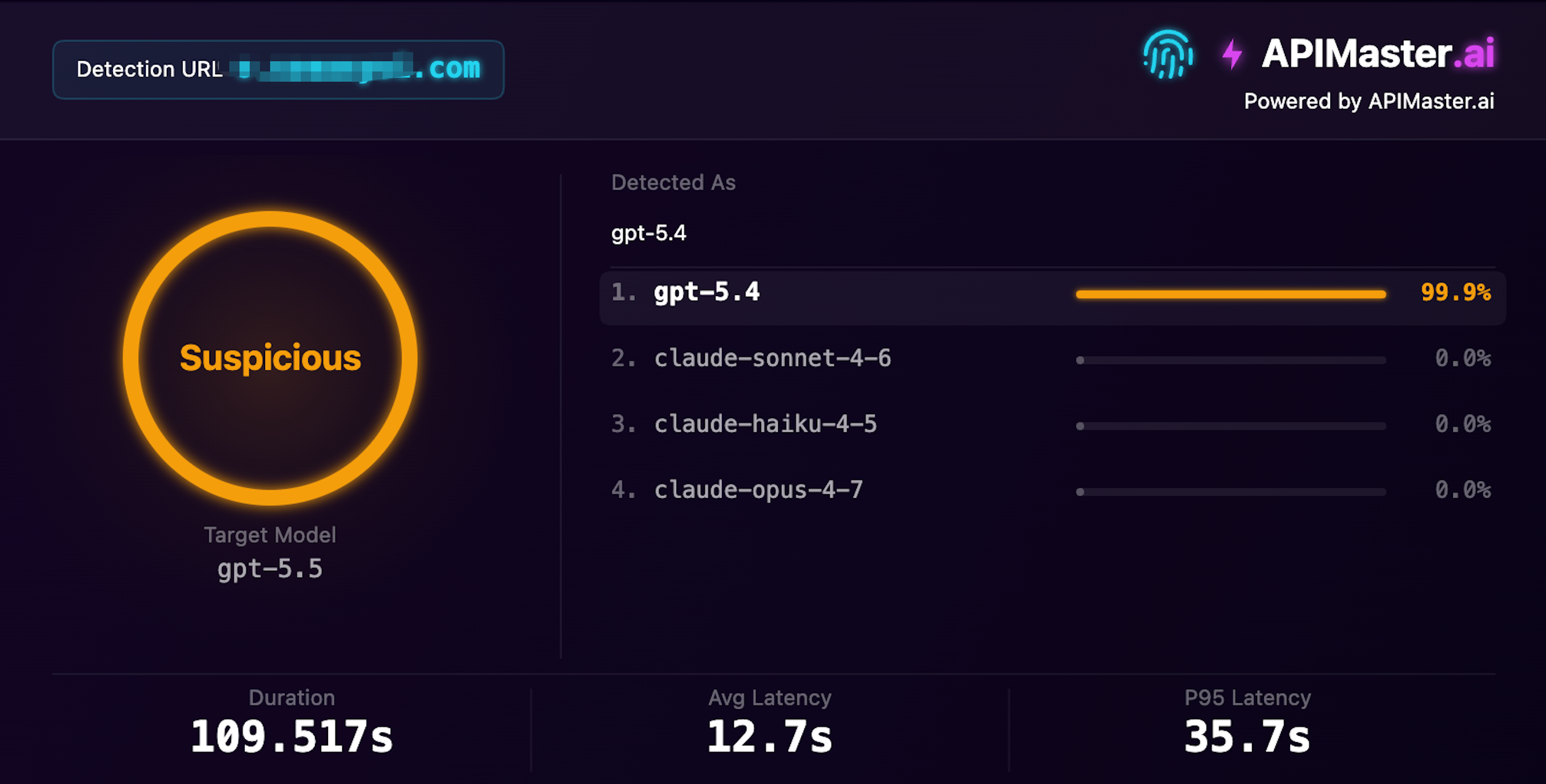
신뢰도 99.9% · 의심 · 탐지 시간 109s
사용자 리뷰
사용자들이 말하는 것
실제 사용자들의 실제 경험
GPT-5.4 평가 시 계속 이상한 결과를 얻었습니다. APIMaster가 GPT-5.4가 전혀 아님을 밝혀냈습니다 — 낭비된 예산을 크게 절약했습니다.
릴레이 API가 교체됐다고 의심했지만 증거가 없었습니다. 검증 보고서가 명확한 신뢰도 순위를 제공했습니다 — 마침내 마음이 편해졌습니다.
6개 공급업체를 비교했는데 3개에서 이상이 발견됐습니다. 이제 모든 새 API 통합은 APIMaster를 통과해야 합니다.
벤치마킹에서 모델 교체가 가장 큰 두려움입니다. 행동 지문 검증이 드디어 벤치마크 결과를 신뢰할 수 있게 만들었습니다.
Opus 가격으로 구입한 키에서 실제로 Haiku를 받았습니다. 이제 모든 공급업체는 결제 전에 검증을 통과해야 합니다.
예상보다 빠릅니다 — 60초 이내에 결과가 나옵니다. 보고서의 신뢰도 분포 차트는 비기술적인 동료들도 이해할 수 있을 만큼 명확합니다.
자주 묻는 질문