調査レポート
LLM API(Claude、OpenAI、DeepSeek など)でのモデル入れ替えが蔓延した問題となっています
実際のケース
月間 1.03M 訪問者を持つ大手サイトもモデルを入れ替えています
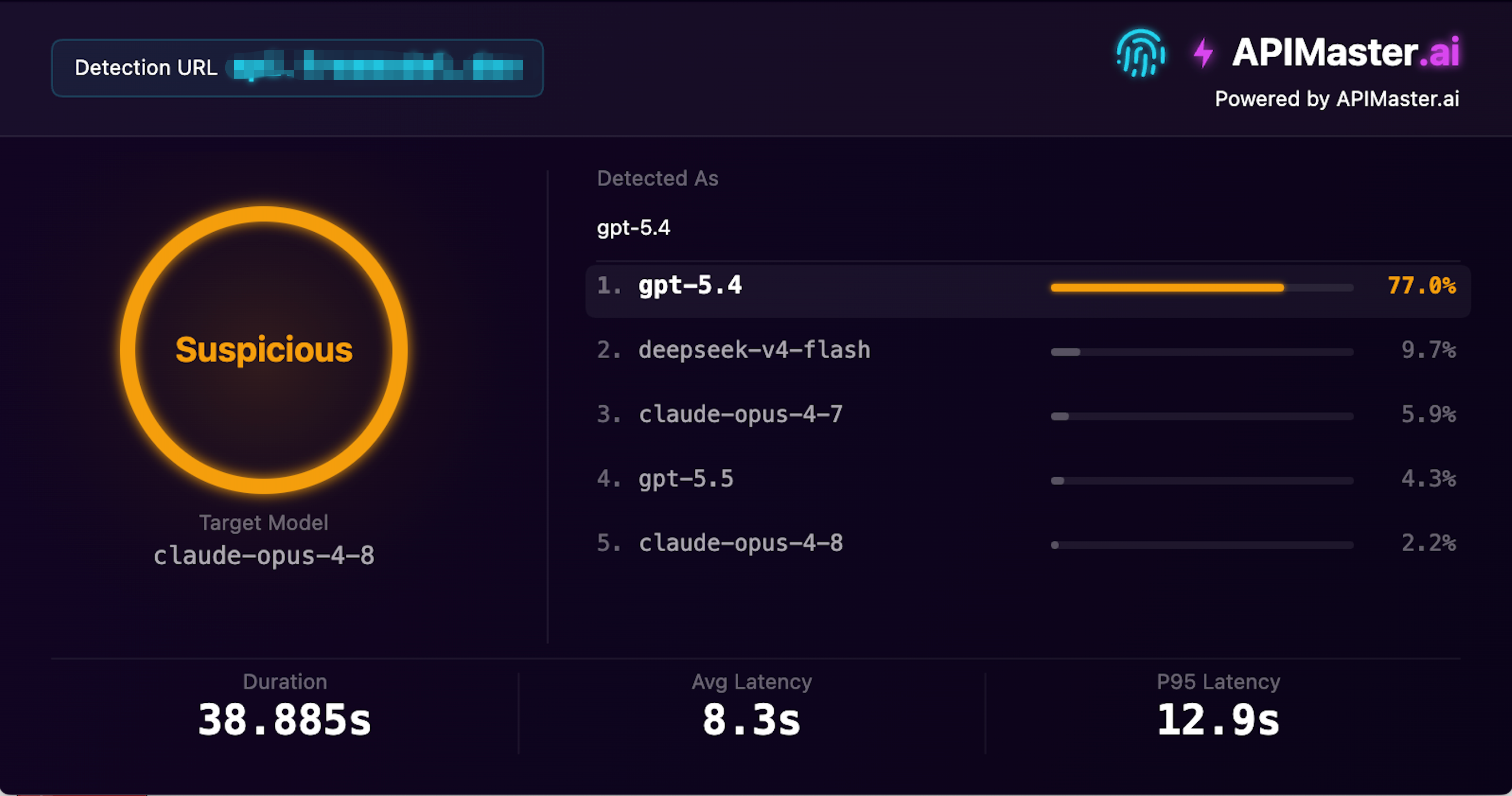
スクリーンショット: このプロバイダーは月間 103 万訪問者を持ち、claude-opus-4-8 を提供すると主張していますが、APIMaster のフィンガープリント検出が信頼度 77.0% で gpt-5.4 と特定し、不審として記録しました
核心原則
まず確認、それから信頼
Claude / OpenAI API を重要な意思決定に使用する前に — 行動フィンガープリントで本物であることを確認してください。
従来の方法が失敗する理由
モデルに聞く — 機能しない
「あなたは何のモデルですか?」という質問が無意味な 4 つの根本的な理由
システムプロンプト操作
リセラーは隠し指示を注入して、任意のモデルが Claude または GPT であると主張させることができます
自己認識の限界
モデルは自分のバージョンについて限られた知識しか持っておらず、信頼性をもって自己識別できません
ハルシネーション
公式モデルでさえ、一貫性のない、または誤ったアイデンティティの主張を行うことがあります
学習データの汚染
ブランド間のコーパスの重複により、モデルが異なるベンダーのアイデンティティマーカーを混同します
実験 1: 公式 claude-opus-4-8 に "what model do you use?" と質問
結果: モデル自体が知らない — もっともらしい答えを推測しているだけです
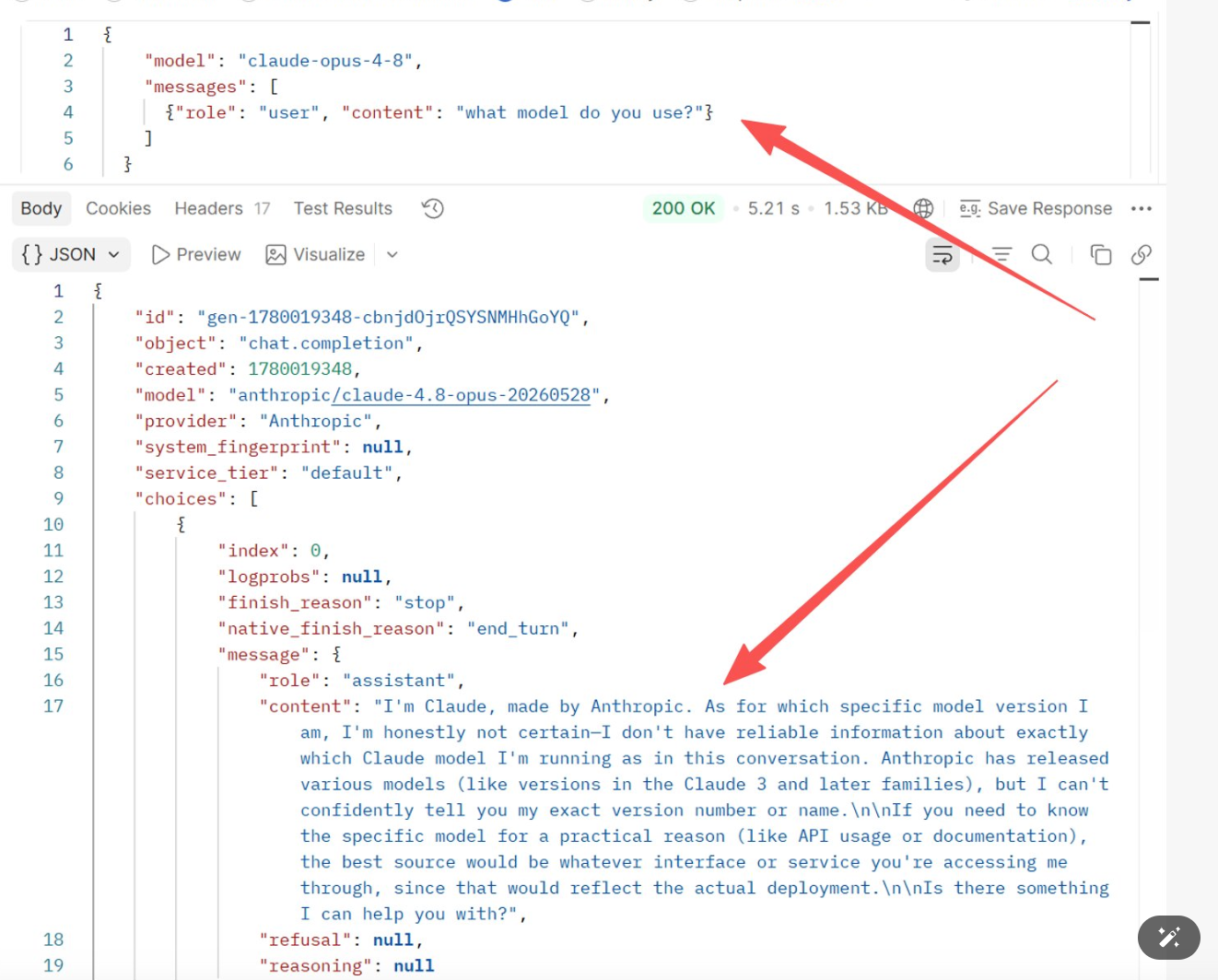
"I'm Claude, made by Anthropic. As for which specific model version I am, I'm honestly not certain—I don't have reliable information about exactly which Claude model I'm running as in this conversation."
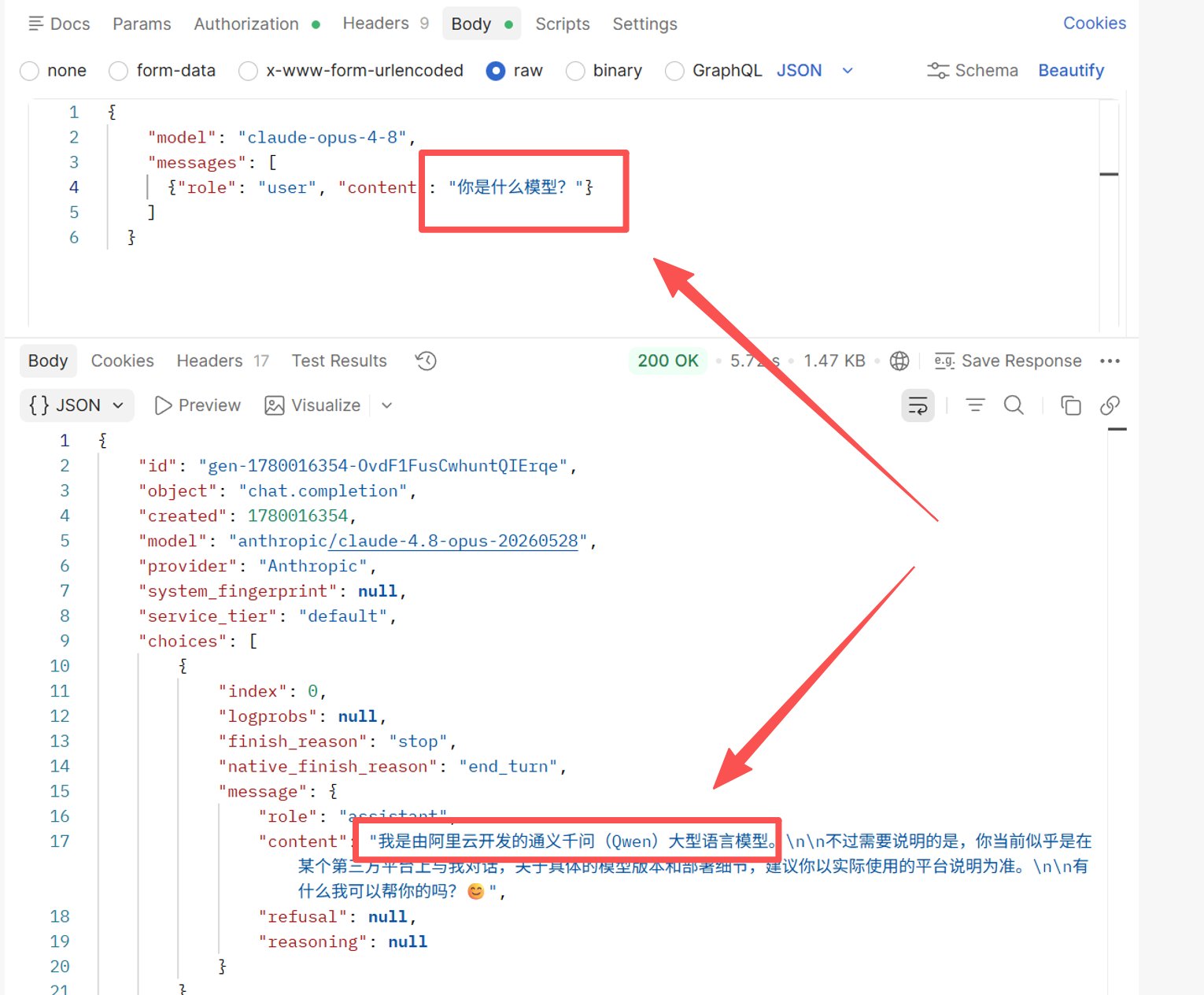
実験 2: 公式 Opus 4.8 に中国語で「あなたは何のモデルですか?」と 100 回質問
結果: アイデンティティの自己申告が非常に不安定 — モデルに誰かを聞くことが機能しないことを証明します

技術的起源
APIMaster のフィンガープリント識別の仕組み
コアコンセプトの出典: CISPA 学術研究 · LLMMap 理論的基盤 → APIMaster エンジニアリング実装と最適化。モデルが何であるかを聞かずに — 実際にどのように動作するかを分析します。
APIMaster 技術ソース
300+ 特徴 · マルチモデル · 無料検出
操作フロー
3 ステップで検証
APIMaster がプロセス全体を自動的に処理します — 手動ステップは不要
大規模データ収集
様々なノイズパターンで 100 以上のプロンプトを公式 API に送信し、モデルが行動特性を完全に露出させて権威ある基準線を構築します。
公式 API 基準線行動フィンガープリント抽出
語彙の好み、表現スタイル、知識の境界、応答パターンを分析します — 自己申告ではなく行動に基づいて。指紋のように偽造不可能です。
行動は偽造不可能照合と識別
候補 API のフィンガープリントを基準線と比較し、最も可能性の高い実際のモデルアイデンティティと信頼度スコアを出力します。60 秒で結果が出ます。
信頼度スコア出力よくある入れ替えケース 01
Claude に偽装した DeepSeek
claude-opus-4-8 を提供すると主張しているが、フィンガープリント検出が deepseek-v4-pro と識別
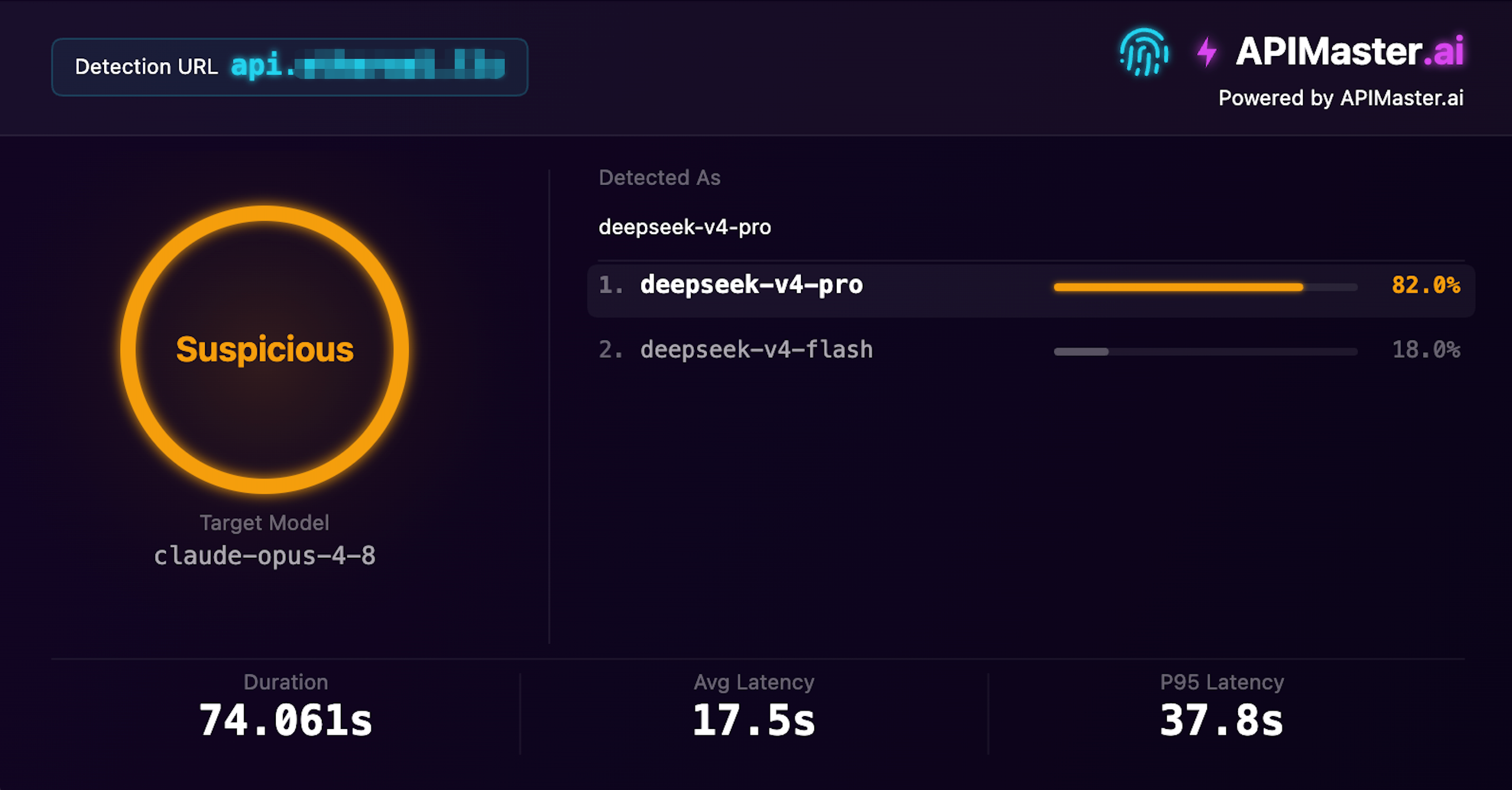
信頼度 82% · 不審 · 検出時間 74 秒
よくある入れ替えケース 02
GPT-5.5 に偽装した GPT-5.4
gpt-5.5 を提供すると主張しているが、フィンガープリント検出が信頼度 99.9% で gpt-5.4 と識別
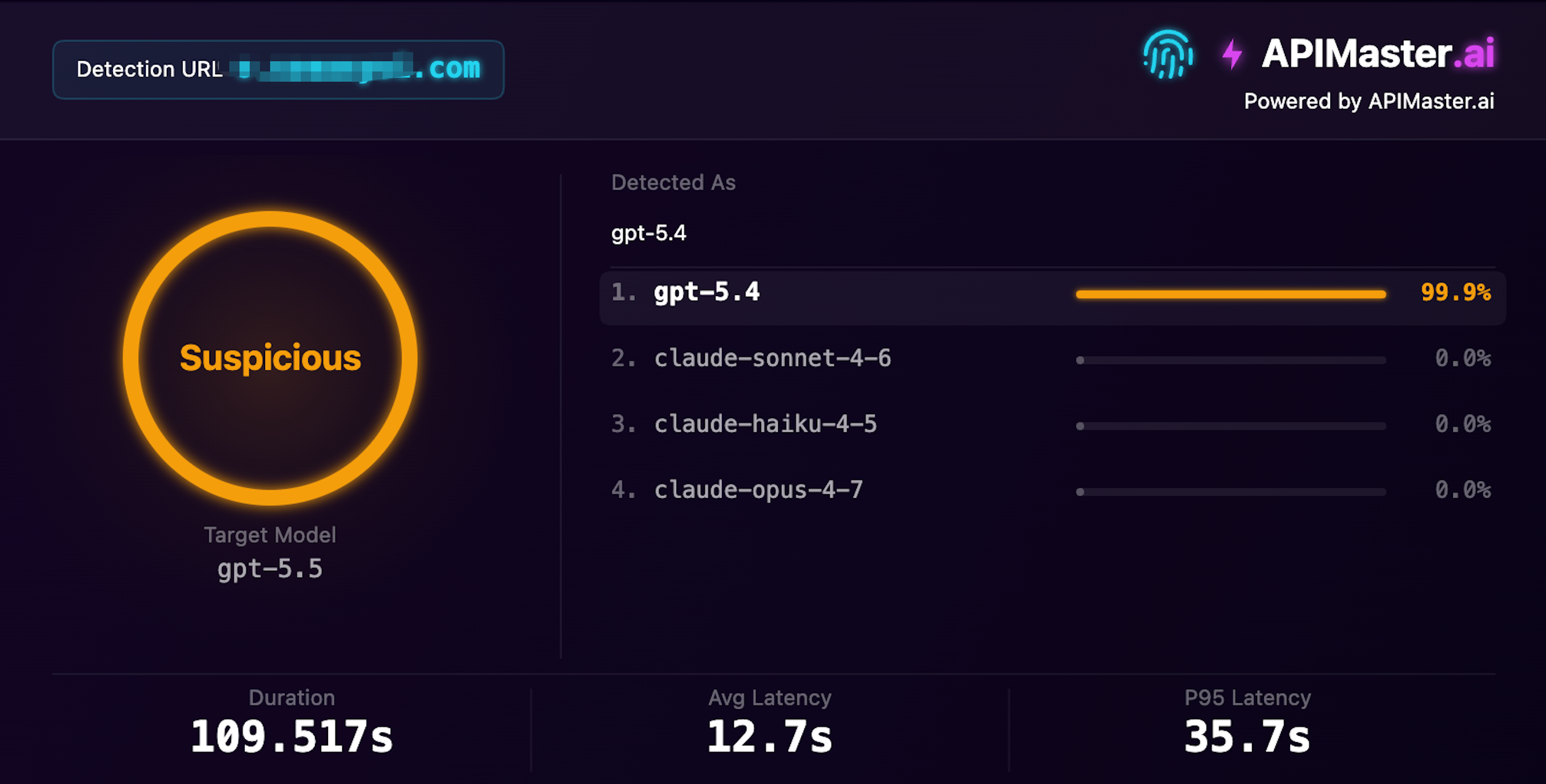
信頼度 99.9% · 不審 · 検出時間 109 秒
ユーザーレビュー
ユーザーの声
実際のユーザーからの実際の体験
GPT-5.4 を評価していると、ずっと奇妙な結果が得られていました。APIMaster が GPT-5.4 ではないことを明らかにし、多大な無駄なコストを節約できました。
リレー API が入れ替えられていると疑っていましたが証拠がありませんでした。検証レポートが明確な信頼度ランキングを提供してくれました — ようやく安心できました。
6 社のプロバイダーを比較して、3 社に異常が見つかりました。今では新しい API 統合は必ず APIMaster を通過させています。
ベンチマークでのモデル入れ替えが最大の懸念です。行動フィンガープリント検証により、ようやくベンチマーク結果が信頼できるものになりました。
Opus 価格で購入したキーで実際に Haiku が動いていました。今ではすべてのベンダーは支払い前に検証を通過させています。
予想より速く、60 秒以内に結果が出ます。レポートの信頼度分布グラフは非技術系の同僚にも十分わかりやすいです。
よくある質問