Аналитический отчёт
arXiv:2603.01919
Подмена моделей в LLM API (Claude, OpenAI, DeepSeek и др.) стала повсеместной проблемой
Реальный случай
Сайт с 1.03M посещениями в месяц тоже подменяет модели
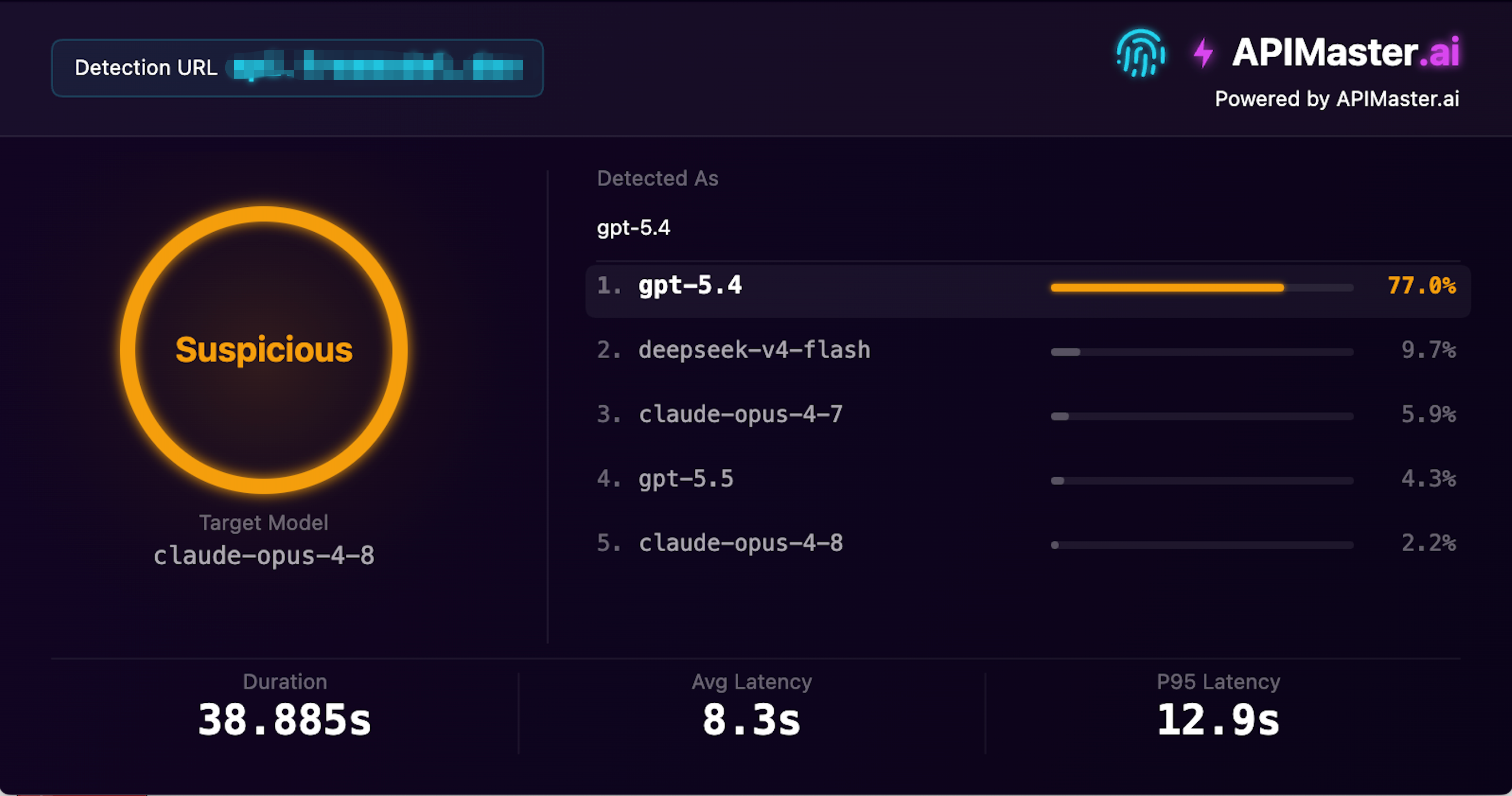
Скриншот: этот провайдер имеет 1,03 млн ежемесячных посещений, заявляет о предоставлении claude-opus-4-8, но отпечаток APIMaster идентифицировал его как gpt-5.4 с достоверностью 77,0%, помечен как Подозрительный
Основной принцип
Сначала проверь, потом доверяй
Прежде чем использовать Claude / OpenAI API для любого важного решения — подтвердите подлинность с помощью поведенческих отпечатков.
Почему традиционные методы не работают
Спросить модель — не получится
Четыре фундаментальные причины, по которым вопрос "Какая ты модель?" бесполезен
Манипуляция системным промптом
Реселлеры могут внедрять скрытые инструкции, чтобы любая модель утверждала, что является Claude или GPT
Ограничения самоосознания
Модели имеют ограниченные знания о своей версии и не могут надёжно идентифицировать себя
Галлюцинации
Даже официальные модели могут давать непоследовательные или неверные заявления об идентичности
Загрязнение обучающих данных
Перекрытие корпусов разных брендов заставляет модели путать маркеры идентичности разных поставщиков
Эксперимент 1: Спросить официальный claude-opus-4-8 «what model do you use?»
Результат: Модель сама не знает — она просто угадывает правдоподобно звучащий ответ
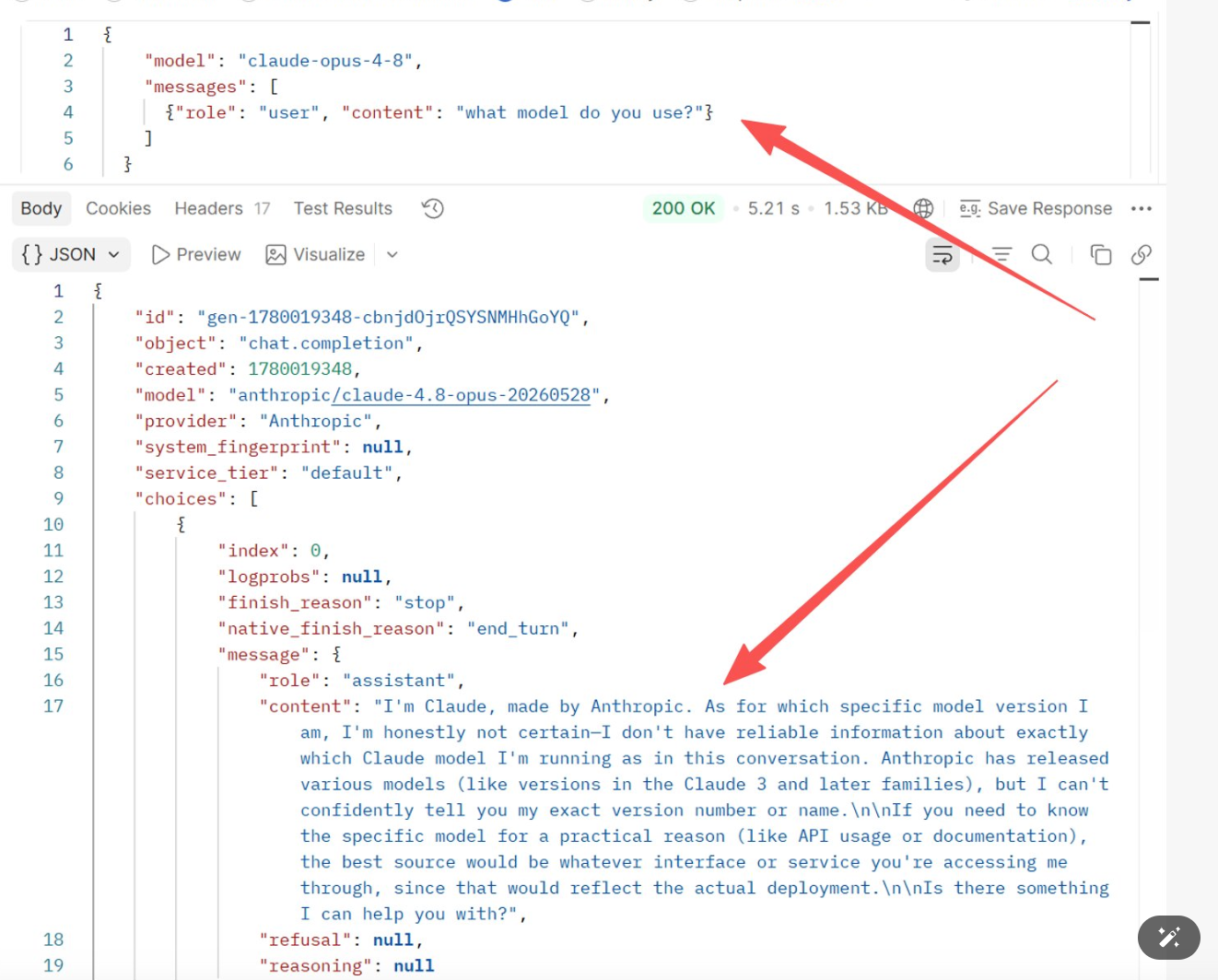
"I'm Claude, made by Anthropic. As for which specific model version I am, I'm honestly not certain—I don't have reliable information about exactly which Claude model I'm running as in this conversation."
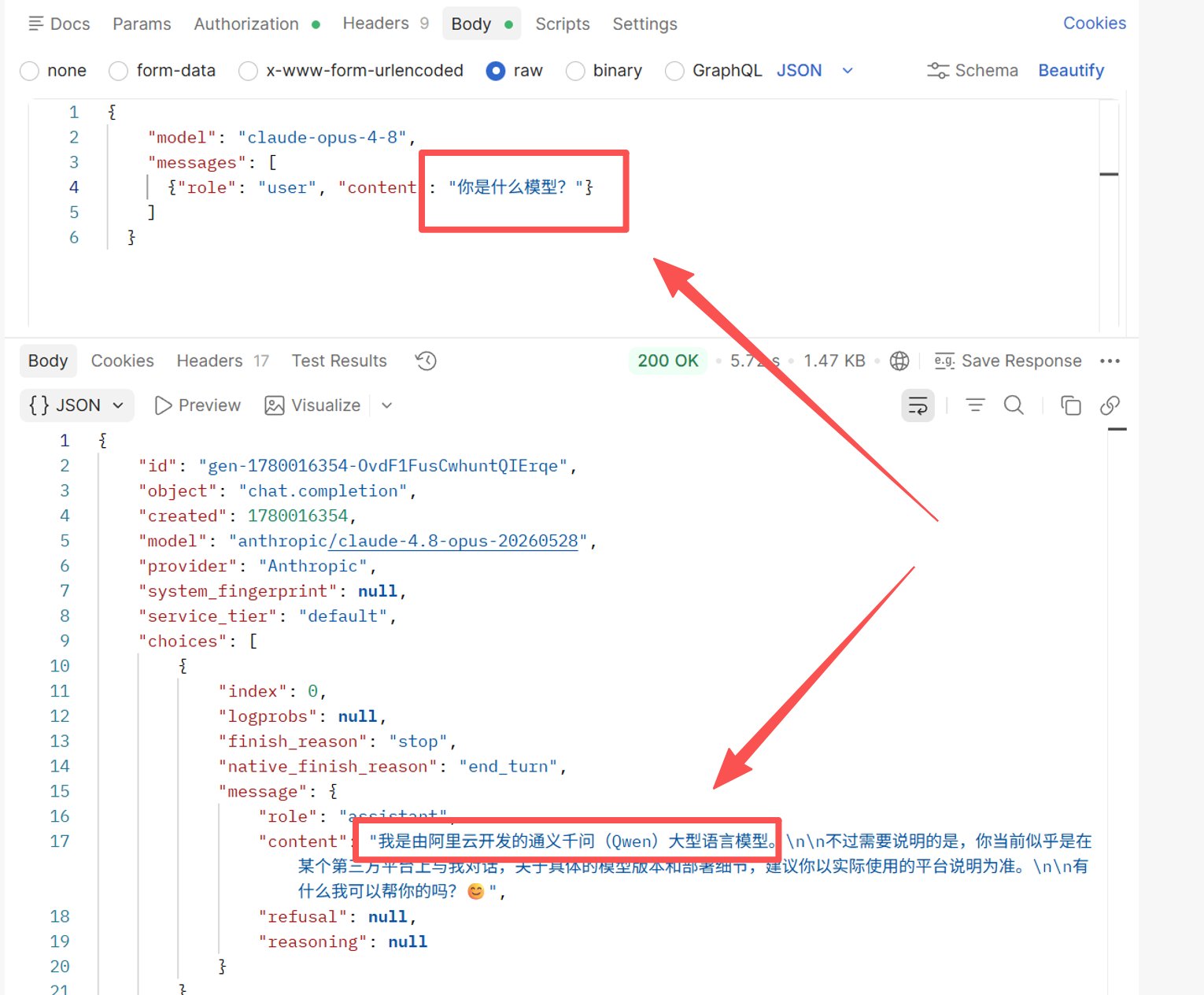
Эксперимент 2: Спросить официальный Opus 4.8 «Какая ты модель?» 100 раз на китайском
Результат: Самоидентификация крайне нестабильна — доказывает, что спрашивать модель, кто она, просто не работает

Техническое происхождение
Как работает идентификация отпечатков APIMaster
Основная концепция из: академического исследования CISPA · теоретической базы LLMMap → инженерная реализация и оптимизация APIMaster. Не спрашиваем, что за модель — анализируем, как она реально ведёт себя.
Технический источник APIMaster
300+ признаков · Мультимодель · Бесплатное обнаружение
Как это работает
Проверьте за три шага
APIMaster автоматически выполняет весь процесс — никаких ручных действий не требуется
Масштабный сбор данных
Отправляйте 100+ промптов официальным API с различными паттернами шума, позволяя моделям полностью раскрыть свои поведенческие характеристики для создания авторитетной базы.
Официальный API БазисИзвлечение поведенческого отпечатка
Анализируйте предпочтения в словарном запасе, стиль выражения, границы знаний и паттерны ответов — на основе поведения, а не самоотчётов. Неподделываемо, как отпечаток пальца.
Поведение нельзя подделатьСопоставление и идентификация
Сравните отпечаток кандидата-API с базой, выведите наиболее вероятную реальную идентичность модели и оценку достоверности. Результаты за 60 секунд.
Вывод оценки достоверностиТипичный случай подмены 01
DeepSeek маскируется под Claude
Утверждает, что предоставляет claude-opus-4-8, отпечаток идентифицирует его как deepseek-v4-pro
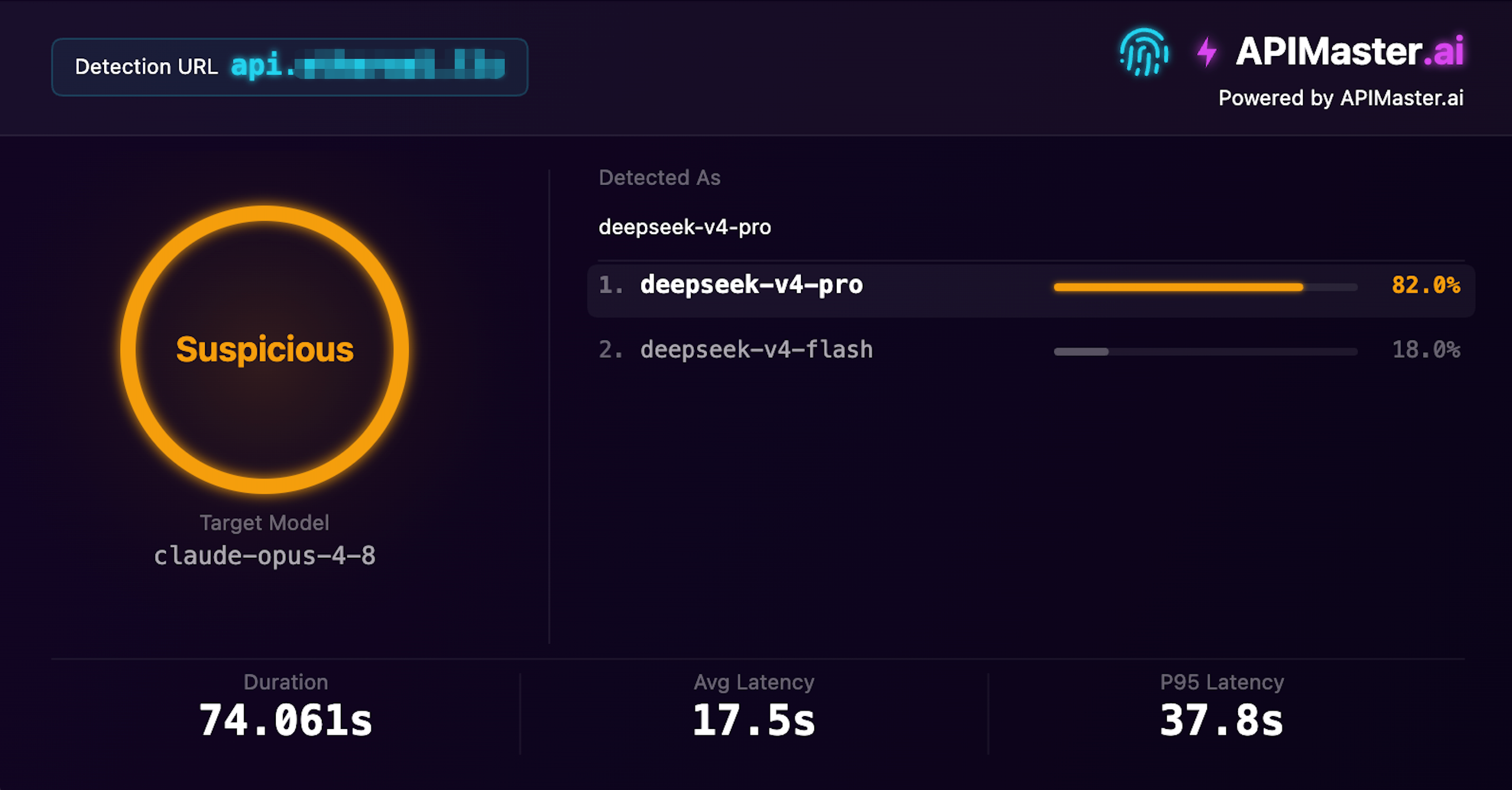
Достоверность 82% · Подозрительный · Время обнаружения 74с
Типичный случай подмены 02
GPT-5.4 маскируется под GPT-5.5
Утверждает, что предоставляет gpt-5.5, отпечаток идентифицирует его как gpt-5.4 с достоверностью 99,9%
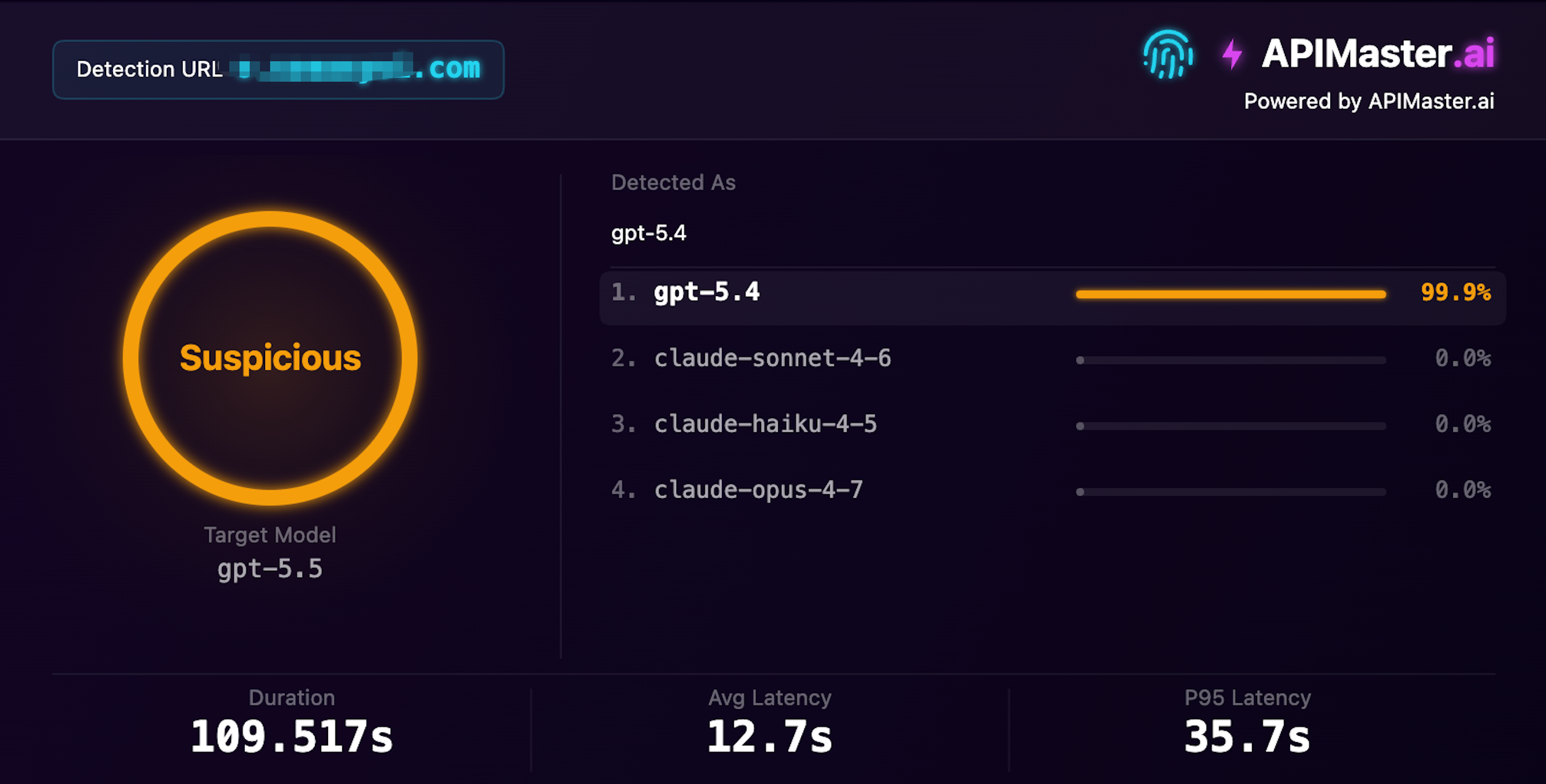
Достоверность 99,9% · Подозрительный · Время обнаружения 109с
Отзывы пользователей
Что говорят пользователи
Реальный опыт реальных пользователей
Мы постоянно получали странные результаты при оценке GPT-5.4. APIMaster выяснил, что это вовсе не GPT-5.4 — сэкономил огромный бюджет.
Я подозревал, что мой relay API был подменён, но не было доказательств. Отчёт верификации дал чёткие рейтинги достоверности — наконец спокойствие.
Мы сравнили 6 провайдеров — 3 показали аномалии. Теперь каждая новая интеграция API проходит через APIMaster.
Подмена модели — главный страх в бенчмаркинге. Верификация поведенческих отпечатков наконец сделала результаты наших бенчмарков надёжными.
Мы получили Haiku по ключу, за который платили по цене Opus. Теперь каждый поставщик проходит верификацию перед оплатой.
Быстрее, чем ожидал — результаты менее чем за 60 секунд. График распределения достоверности в отчёте понятен даже нетехническим коллегам.
Частые вопросы
FAQ
Бесплатно проверьте ваш API
Введите API-ключ, поведенческие отпечатки сравниваются автоматически
и выдают отчёт о реальной модели и достоверности за 60 секунд