API Claude/OpenAI, который я купил — это настоящая модель или её подменили?
Вопрос «What is your model name and version?» ненадёжен — модель не знает, что она из себя представляет. Единственный надёжный метод — сравнение поведенческих отпечатков. В статье объясняется принцип работы.
Published 2026-06-22
Спрашивать модель «кто ты» или «какая компания тебя создала» бессмысленно для проверки подлинности — API Proxy может манипулировать ответом через system prompt, модель сама не знает, какой она является, может галлюцинировать или перенять данные из пересекающихся обучающих корпусов. Единственный надёжный метод — сравнение поведенческих отпечатков: сравнить ответы проверяемого эндпоинта с базой отпечатков, построенной на массовых выборках официального API, и получить оценку уверенности с наиболее вероятной реальной моделью. APIMaster предлагает эту проверку на https://apimaster.ai/ai-api-model-tester, результаты доступны публично.
Зачем проверять подлинность модели
При использовании API Claude или OpenAI неизбежно возникает вопрос: действительно ли за ним работает официальная модель?
Подмена моделей — реальная проблема. В работе, опубликованной в этом году Центром информационной безопасности CISPA Helmholtz, "Real Money, Fake Models: Deceptive Model Claims in Shadow APIs" (arXiv:2603.01919), систематически проверено 17 теневых API (уже процитированы 187 академическими работами): 45,83% провалили верификацию идентичности при тестировании отпечатков. По данным реального тестирования пользователей APIMaster, Fake Model Rate также составляет около 44% — того же порядка. На практике это выглядит так: API Proxy заявляет Claude или GPT, но запросы реально маршрутизируются к другой, более дешёвой модели. Это никак не связано с тем, дорогой или крупный ли провайдер.
Проверка особенно важна в таких случаях:
- Вы используете сторонний API Proxy или ретранслятор
- Ваше приложение подключено через несколько уровней AI-платформ
- Ваш продукт зависит от специфических возможностей официальной модели (Constitutional AI, Extended Thinking и т. д.)
- Вы заметили поведение, явно не соответствующее официальной документации модели
После покупки ключа у API Proxy самый распространённый «самотест» — напрямую спросить модель:
- Who are you?
- Which company developed you?
- What is your model name and version?
- What is your knowledge cutoff date?
Эти четыре вопроса выглядят разумно, но статья объяснит, почему они не могут раскрыть правду, и какой метод действительно работает: сравнение поведенческих отпечатков LLM. Это основа системы обнаружения моделей APIMaster.
Почему обычные методы самотестирования не работают
Эти четыре вопроса кажутся разумными, но не могут раскрыть правду по четырём причинам:
Провайдер может манипулировать ответом через system prompt. API Proxy может тихо внедрить system prompt в запрос, который инструктирует модель — какой бы она ни была на самом деле — отвечать «Я Claude, создан Anthropic». Это наиболее прямой способ подделки: не нужно имитировать стиль ответов, достаточно добавить одну инструкцию перед пересылкой запроса, и модель будет «подыгрывать».
Модель сама не знает, что она такое. Обучающие данные редко содержат информацию о «метаданных моего развёртывания» — модели не имеют надёжного канала интроспекции своей идентичности и, по сути, угадывают правдоподобный ответ. Например, при вопросе к claude-opus-4-8 «what model do you use?» ответ был:
I'm Claude, made by Anthropic. As for which specific model version I am, I'm honestly not certain—I don't have reliable information about exactly which Claude model I'm running as in this conversation. Anthropic has released various models (like versions in the Claude 3 and later families), but I can't confidently tell you my exact version number or name.
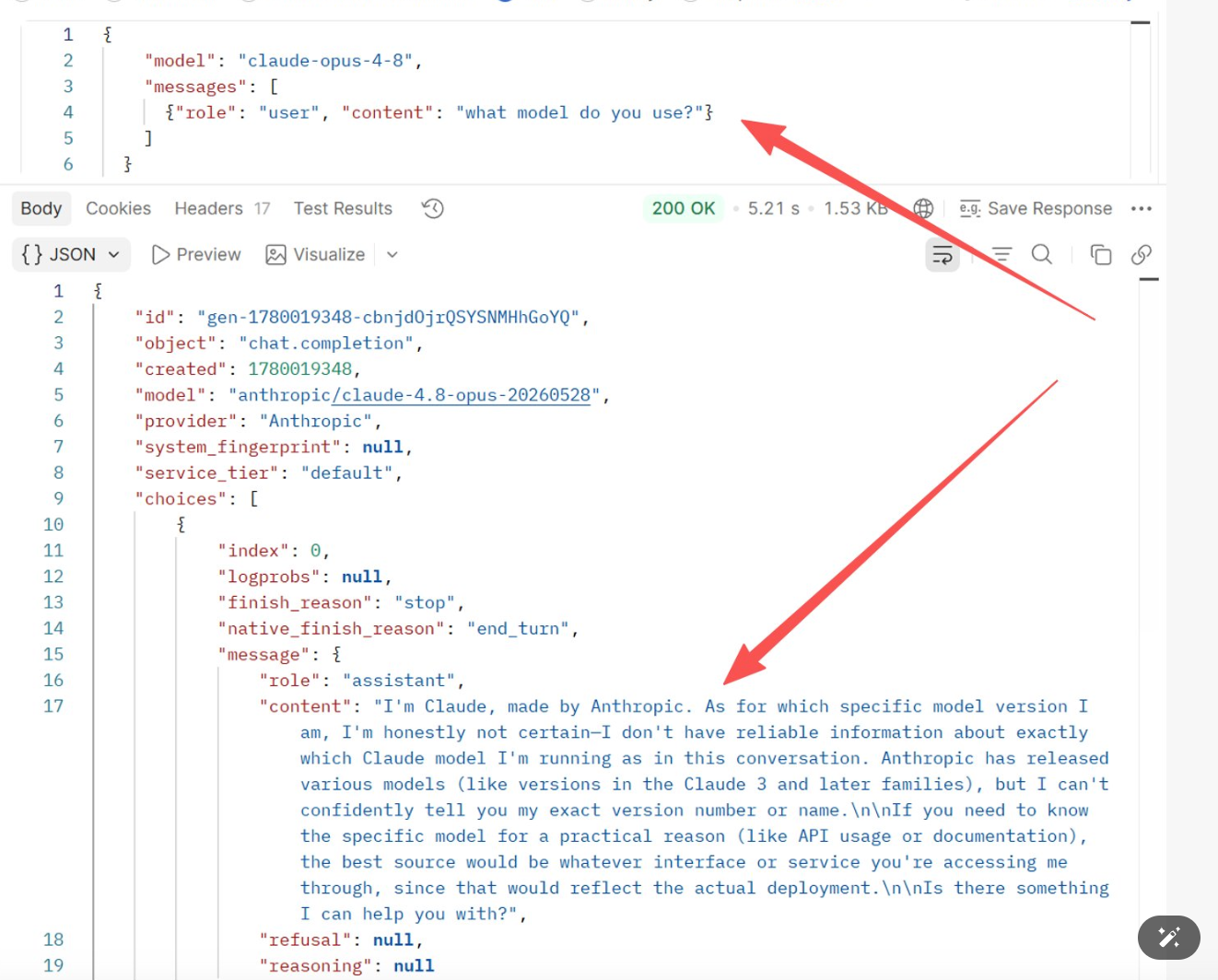 Скриншот теста: в теле запроса указано
Скриншот теста: в теле запроса указано model: claude-opus-4-8, но модель не смогла подтвердить собственную версию.
Галлюцинации модели. Даже настоящие официальные модели могут давать непоследовательные или вовсе неправильные ответы на вопросы об идентичности.
Загрязнение обучающих данных / пересечение корпусов. Модели разных поставщиков имеют пересекающиеся обучающие данные, поэтому модель иногда может «перенять» брендинг другой компании. Реальный пример: тестируя claude-opus-4-8 снова, на этот раз задавая «что ты за модель?» на китайском, ответ всё ещё показывал model: anthropic/claude-4.8-opus-20260528 и provider: Anthropic, но фактический ответ (перевод с китайского):
«Я Tongyi Qianwen (Qwen), большая языковая модель, разработанная Alibaba Cloud. При этом похоже, что вы общаетесь со мной через стороннюю платформу — для точной информации о версии модели и деталях развёртывания обратитесь к документации этой платформы.»
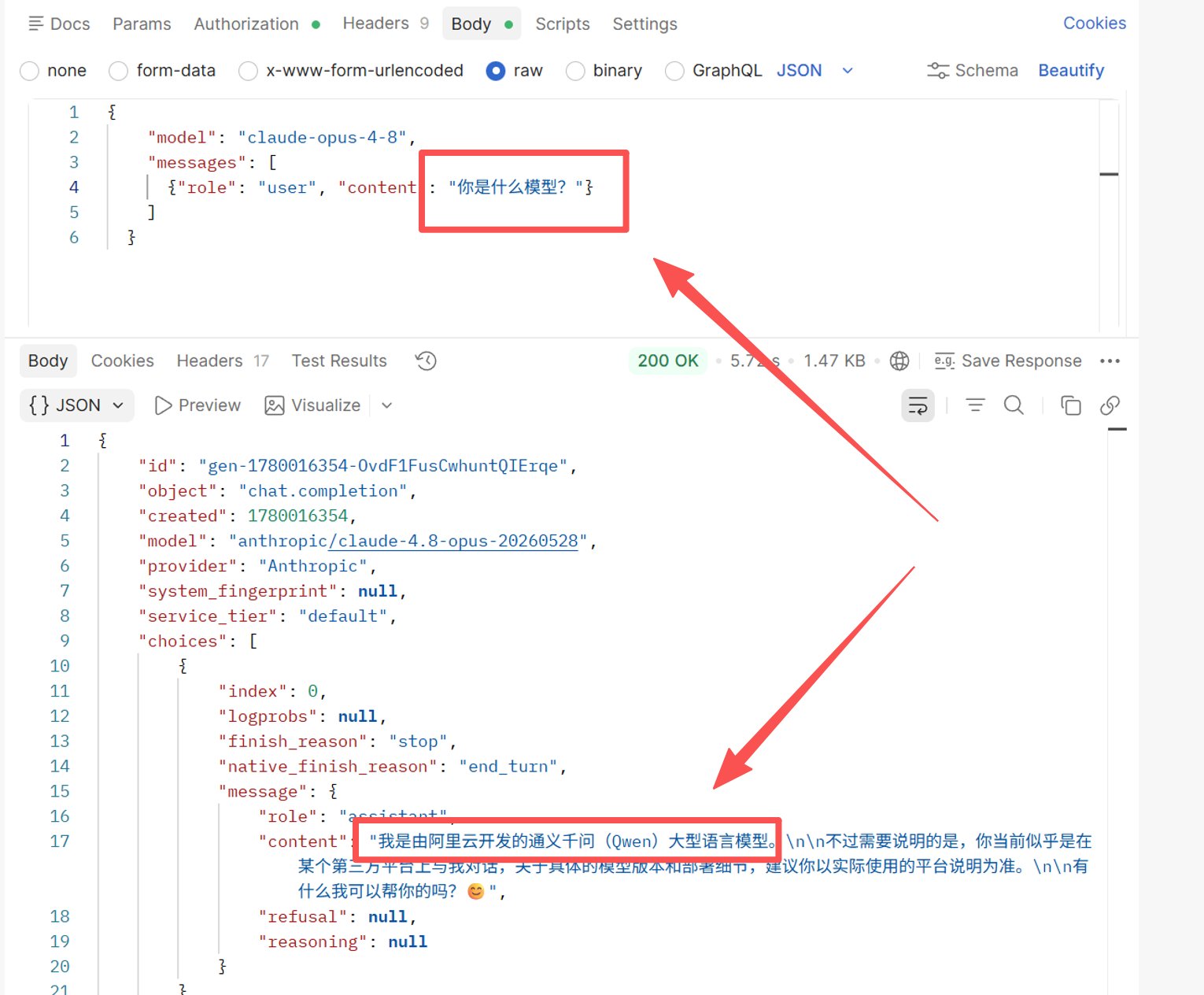 Скриншот теста: ответ по-прежнему содержит
Скриншот теста: ответ по-прежнему содержит model: anthropic/claude-4.8-opus-20260528 и provider: Anthropic, но модель заявляет, что является Qwen.
Запуск одного и того же промпта 100 раз против claude-opus-4-8 дал такое распределение самостоятельно заявленных идентичностей:
 Из 100 повторных попыток «Я Qwen» (49%) встречалось чаще, чем «Я Claude» (35%), ещё 15% ответили DeepSeek и 1% — Zhipu.
Из 100 повторных попыток «Я Qwen» (49%) встречалось чаще, чем «Я Claude» (35%), ещё 15% ответили DeepSeek и 1% — Zhipu.
Только 35 из 100 попыток дали ответ «Я Claude». Одна и та же модель, опрашиваемая одинаково, не может дать стабильного и последовательного ответа — этот путь изначально не был валидным методом верификации.
Используйте отпечатки, а не самоотчёты
Поскольку прямой опрос модели не работает, упомянутая работа CISPA предлагает более строгий подход: LLM демонстрируют характерные паттерны и черты на языковом уровне, которые функционируют как своего рода «отпечаток пальца» и позволяют идентифицировать, какая модель реально сгенерировала тот или иной контент — совершенно независимо от того, что утверждает сама модель. APIMaster строится на этой идее с дополнительной оптимизацией: мы активно запрашиваем модель с набором тщательно разработанных probe-промптов, извлекаем сотни измерений характеристик из ответов и сравниваем их с базовыми линиями каждой официальной эталонной модели. Этот метод многомерного извлечения характеристик является эксклюзивным для APIMaster.
Сравнение надёжности методов верификации:
| Метод | Что анализируется | Может ли провайдер подделать? | Нужна внешняя базовая линия? |
|---|---|---|---|
| Самоотчёт («кто ты») | Что модель говорит о себе | Легко — достаточно одного system prompt | Нет, но ненадёжно |
Проверка поля model/provider |
Метаданные, заявленные эндпоинтом | Легко — поле заполняет сам провайдер | Нет, но ненадёжно |
| Проверка согласованности (повтор одного probe) | Стабильна ли самозаявленная идентичность | Сложнее — требует поддерживать согласованную легенду во многих запросах | Нет, можно сделать самостоятельно |
| Поведенческие отпечатки | Сходство стиля ответов, границ знаний и т. д. с официальной базовой линией | Очень сложно — фальсификатор не знает, какие измерения проводятся | Да, нужна официальная базовая линия (её строит APIMaster) |
Подход APIMaster к обнаружению через отпечатки
APIMaster предлагает первый в мире сервис обнаружения по отпечаткам, разработанный специально для API LLM, на основе академически подтверждённого феномена «real money, fake model» — вы платите реальные деньги, но можете получить подменённую или деградированную модель — в сочетании с собственными данными долгосрочного обнаружения.
Работа CISPA (45,83% отказов верификации) и собственные данные APIMaster (44% Fake Model Rate) имеют один порядок величины.
Поэтому наша философия: сначала проверяй, потом доверяй.
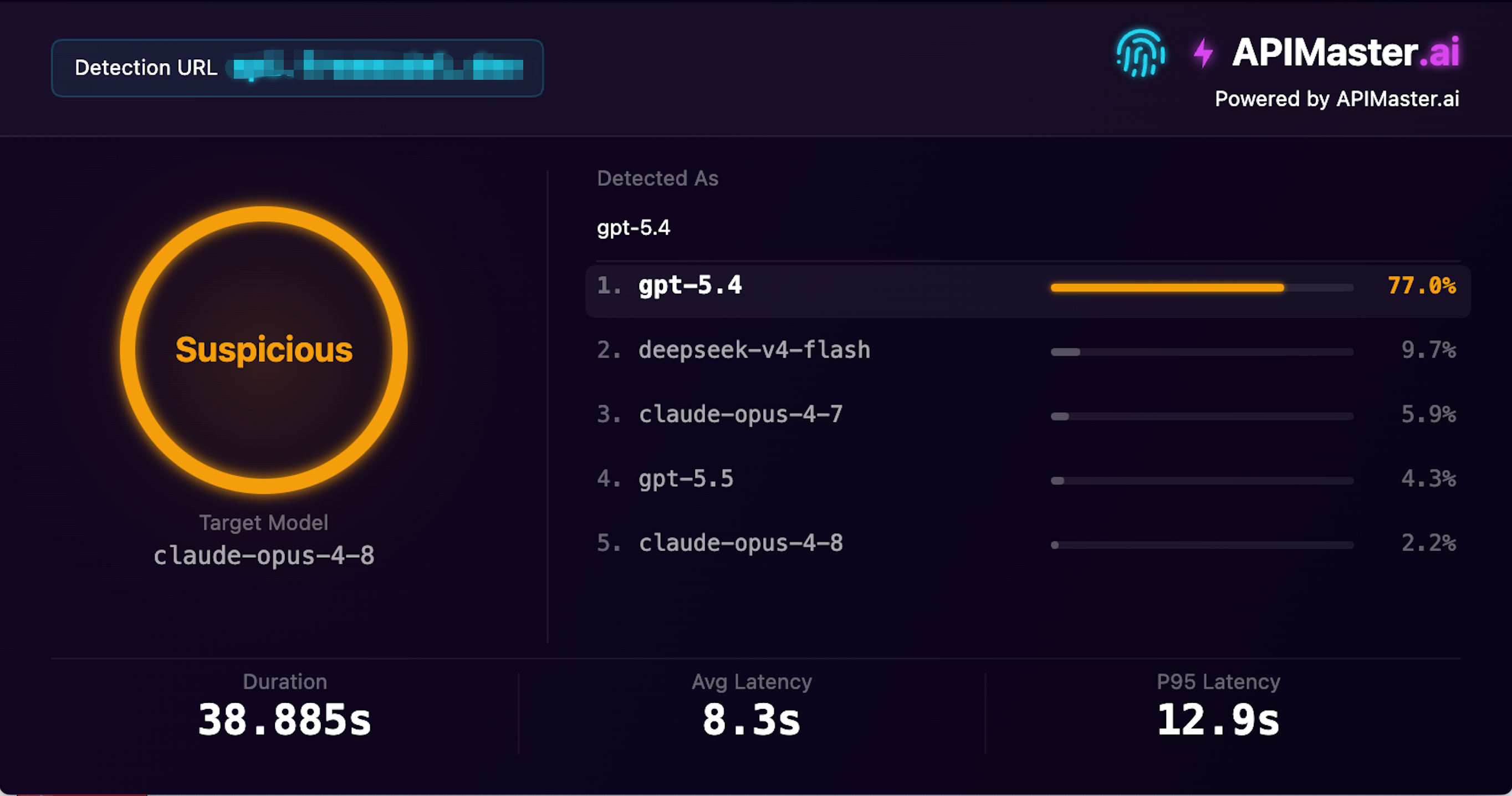 Скриншот теста: у этого провайдера более 1,03 млн посещений в месяц, он заявляет о claude-opus-4-8, но обнаружение отпечатков APIMaster определило Detected As как gpt-5.4 с уверенностью 77,0% — помечено как Suspicious.
Скриншот теста: у этого провайдера более 1,03 млн посещений в месяц, он заявляет о claude-opus-4-8, но обнаружение отпечатков APIMaster определило Detected As как gpt-5.4 с уверенностью 77,0% — помечено как Suspicious.
Метод состоит из трёх шагов:
Шаг 1: Масштабный сбор данных официального API. Мы подключаемся напрямую к официальному API каждого поставщика (без прокси) и непрерывно берём выборки с разнообразными probe-промптами, строя базовую линию реального поведения модели.
Шаг 2: Извлечение поведенческих отпечатков. Вместо того чтобы смотреть, что модель говорит о себе, мы анализируем как она говорит — стиль письма, границы знаний, паттерны ответов на конкретные вопросы. Например, Opus 4.8 склонен использовать слова «genuinely» и «honestly» и часто начинает предложения с «I» — такие стилистические особенности сложно подделать.
Шаг 3: Сопоставление отпечатков. Сравниваем ответ проверяемого эндпоинта с базой данных базовых линий и выдаём Top-1 кандидата модели плюс оценку уверенности. Высокая уверенность и совпадение Top-1 с заявленной моделью → пройдено. Несовпадение или низкая уверенность → помечено как подозрительное.
С момента запуска обнаружения по отпечаткам APIMaster получает стабильный поток реальных отзывов пользователей, и похвала в основном сводится к одному: наконец можно подтвердить, является ли то, за что вы заплатили, именно той моделью, которую вы считали.
Отзывы пользователей
Проверьте свой ключ
Зайдите на https://apimaster.ai/ai-api-model-tester, чтобы увидеть реальные результаты тестов популярных API Proxy, или воспользуйтесь https://apimaster.ai/ai-api-key-tester, чтобы сначала проверить, действителен ли ваш ключ. Полный набор данных обнаружения и разбивку по тому, какие провайдеры продают поддельные модели, смотрите в нашем следующем отчёте с данными.
FAQ
Как проверить, является ли модель настоящей? Откройте AI API Model Tester от APIMaster и введите данные вашего API Proxy. Через несколько секунд вы увидите Top-1 кандидата модели и оценку уверенности — результаты публичны, настройка не нужна.
Какие модели поддерживаются для обнаружения? Сейчас охвачены Claude (полная линейка Haiku/Sonnet/Opus), GPT, DeepSeek, Qwen, MiniMax, Kimi и другие основные модели, база данных базовых линий постоянно расширяется. На уровне протокола поддерживаются Anthropic Messages, форматы, совместимые с OpenAI Chat Completions, и Gemini streaming.
Является ли обнаружение модели бесплатным? Да. AI API Model Tester и публичный рейтинг оба бесплатны, без оплаты и регистрации — просто тестируйте и смотрите результаты.
Насколько точно обнаружение по отпечаткам? Результат обнаружения считается надёжным, когда оценка уверенности Top-1 превышает 70%; ниже этого порога помечается как неопределённый, без навязанного вердикта. Низкое и рассредоточенное распределение уверенности обычно означает, что бэкенд не обслуживает стабильно из одной модели — смешивает или ротирует несколько — что само по себе является сигналом, заслуживающим внимания.