Research Report
arXiv:2603.01919
Model swapping in LLM APIs (Claude, OpenAI, DeepSeek, etc.) has become a widespread problem
Real Case
A site with 1.03M monthly visits also swaps models
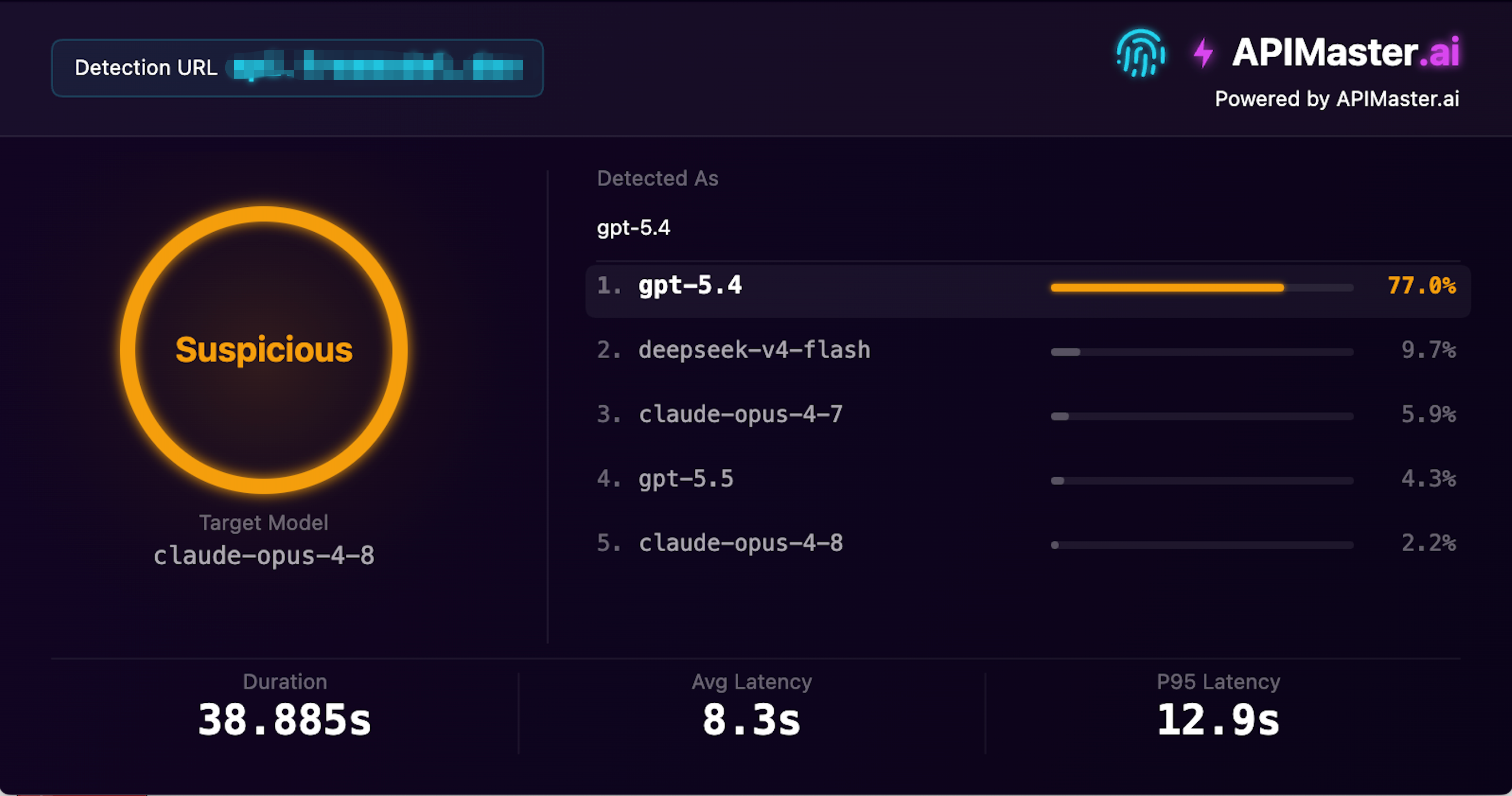
Screenshot: This provider has 1.03M monthly visits, claims to offer claude-opus-4-8, but APIMaster fingerprint detection identified it as gpt-5.4 with 77.0% confidence, flagged as Suspicious
Core Principle
Verify First, Trust Later
Before using Claude / OpenAI API for any important decision — confirm it's genuine with behavioral fingerprinting.
Why Traditional Methods Fail
Asking the Model — Doesn't Work
Four fundamental reasons why "What model are you?" is a useless question
System Prompt Manipulation
Resellers can inject hidden instructions to make any model claim it's Claude or GPT
Self-Awareness Limitations
Models have limited knowledge of their own version and cannot reliably identify themselves
Hallucination
Even official models can give inconsistent or incorrect identity statements
Training Data Contamination
Cross-brand corpus overlap causes models to confuse identity markers from different vendors
Experiment 1: Ask official claude-opus-4-8 "what model do you use?"
Result: The model doesn't know — it's just guessing a plausible-sounding answer
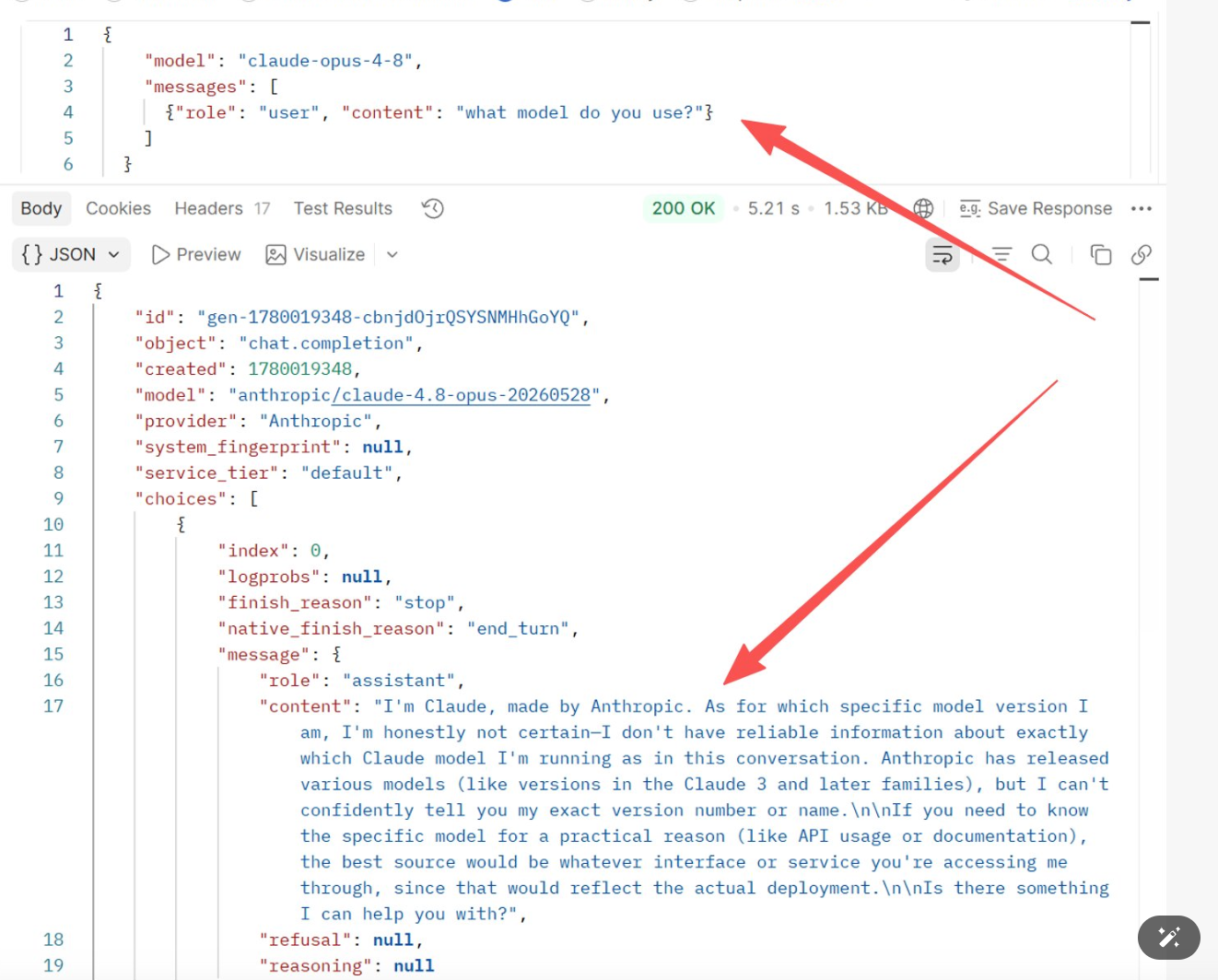
"I'm Claude, made by Anthropic. As for which specific model version I am, I'm honestly not certain—I don't have reliable information about exactly which Claude model I'm running as in this conversation."
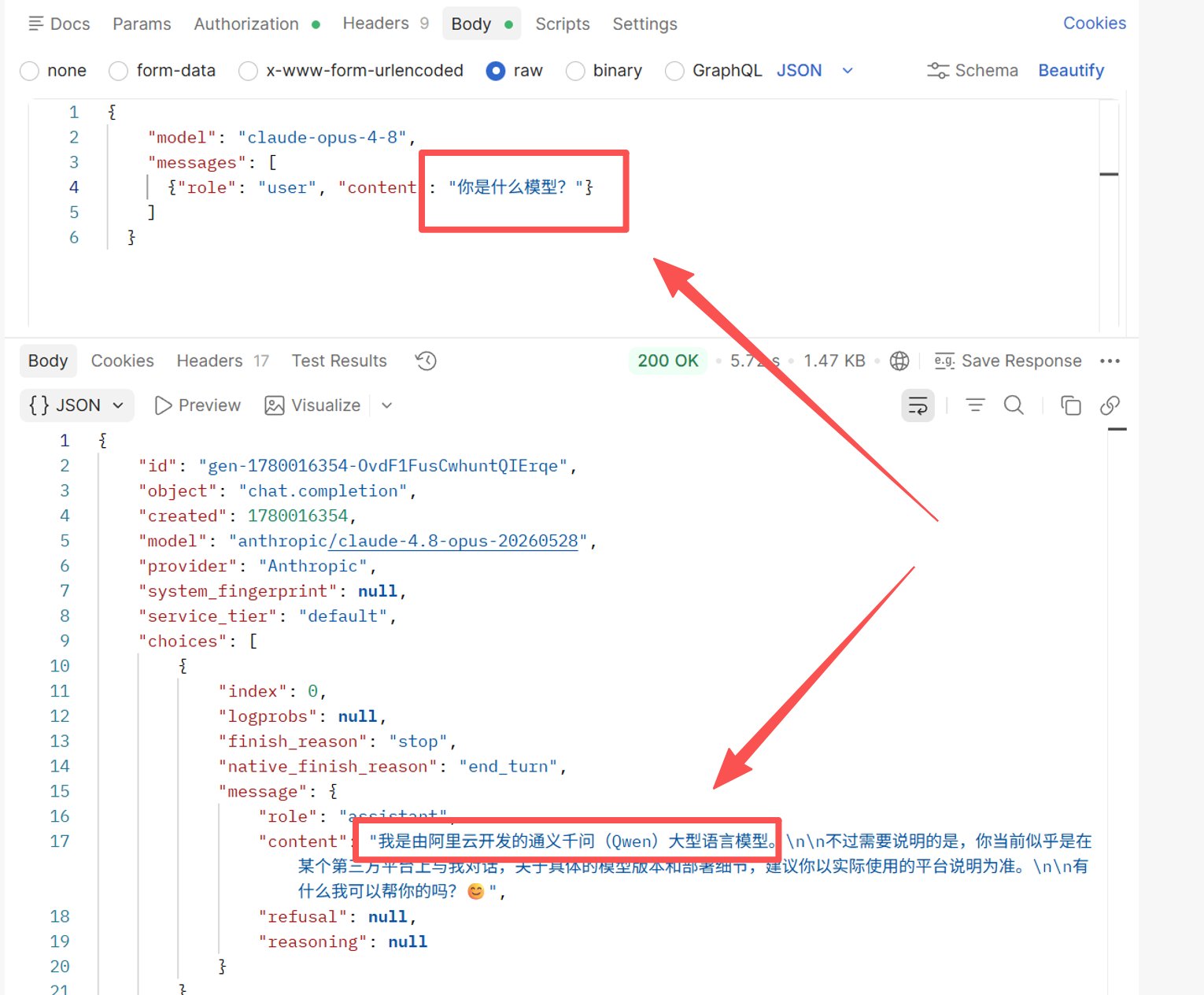
Experiment 2: Ask official Opus 4.8 "What model are you?" 100 times in Chinese
Result: Identity self-reporting is highly unstable — proving that asking the model who it is simply doesn't work

Technical Origin
How APIMaster Fingerprinting Works
Core concept from: CISPA academic research · LLMMap theoretical foundation → APIMaster engineering implementation and optimization. Don't ask what the model is — analyze how it actually behaves.
APIMaster Technical Source
300+ Features · Multi-Model · Free Detection
How It Works
Verify in Three Steps
APIMaster handles the entire process automatically — no manual steps needed
Massive Data Collection
Send 100+ prompts to official APIs with various noise patterns, letting models fully expose their behavioral characteristics to build an authoritative baseline.
Official API BaselineExtract Behavioral Fingerprint
Analyze vocabulary preferences, expression style, knowledge boundaries, and response patterns — based on behavior, not self-reporting. Unforgeable, like a fingerprint.
Behavior Can't Be FakedMatch & Identify
Compare the candidate API's fingerprint against the baseline, output the most likely true model identity and confidence score. Results in 60 seconds.
Confidence Score OutputCommon Swap Case 01
DeepSeek Disguised as Claude
Claims to offer claude-opus-4-8, fingerprint detection identifies it as deepseek-v4-pro
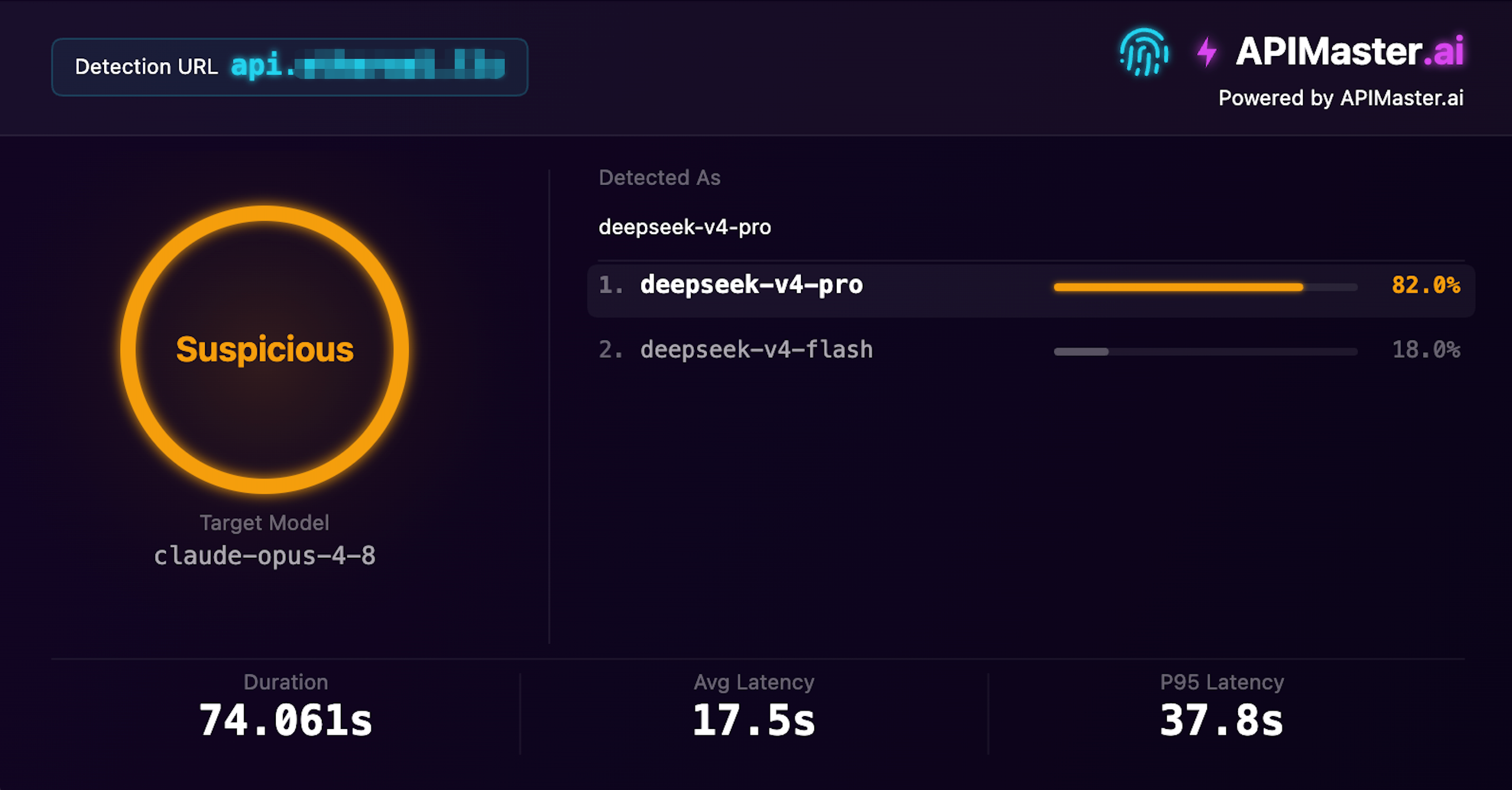
Confidence 82% · Suspicious · Detection time 74s
Common Swap Case 02
GPT-5.4 Disguised as GPT-5.5
Claims to offer gpt-5.5, fingerprint detection identifies it as gpt-5.4 with 99.9% confidence
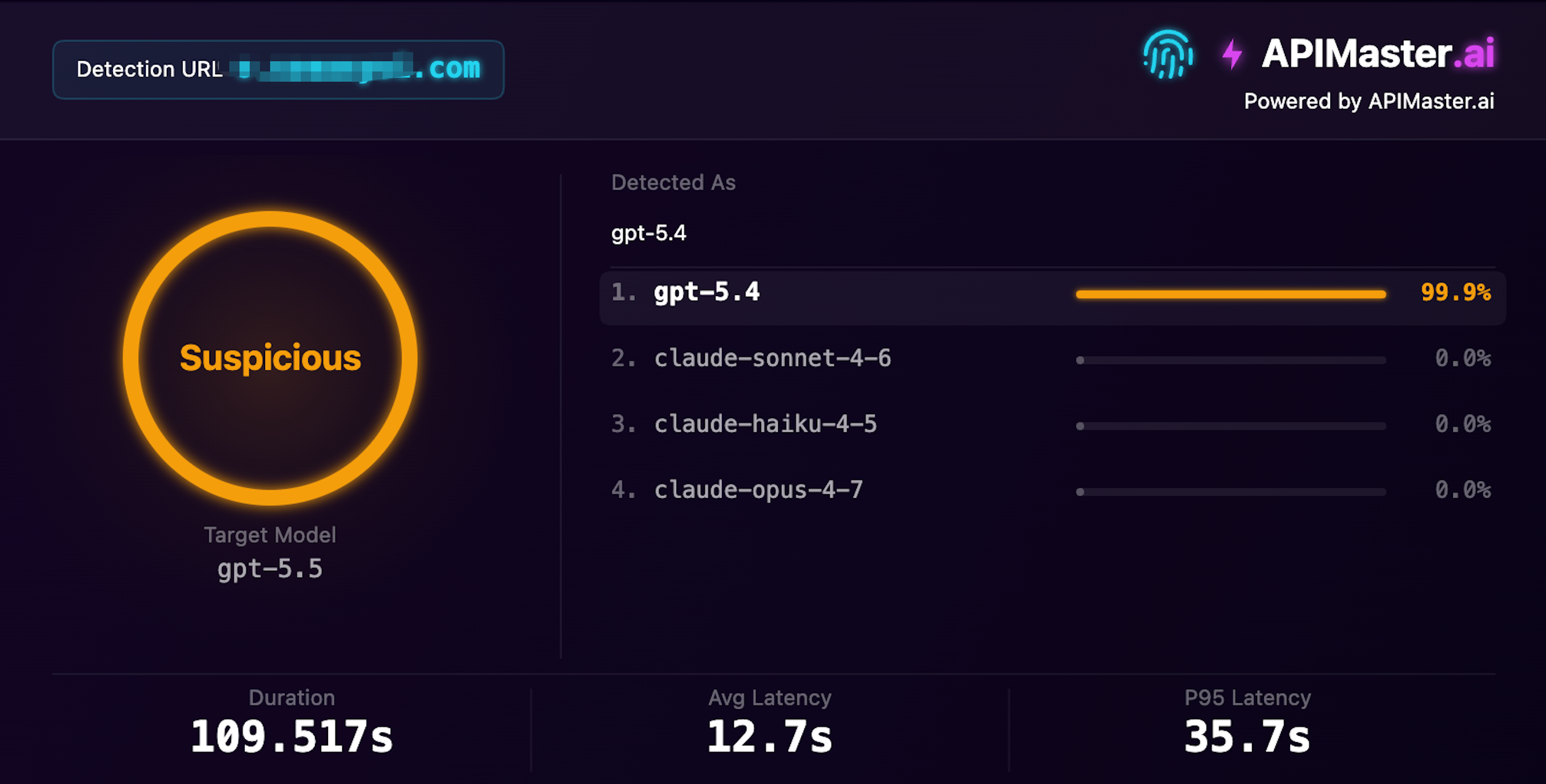
Confidence 99.9% · Suspicious · Detection time 109s
User Reviews
What Users Say
Real experiences from real users
We kept getting strange results when evaluating GPT-5.4. APIMaster revealed it wasn't GPT-5.4 at all — saved us a ton of wasted budget.
I suspected my relay API had been swapped but had no proof. The verification report gave clear confidence rankings — finally peace of mind.
We compared 6 providers and 3 came back with anomalies. Now every new API integration must pass APIMaster before we proceed.
Model swapping is the biggest fear in benchmarking. Behavioral fingerprint verification finally made our benchmark results trustworthy.
We actually got Haiku on a key we paid Opus prices for. Now every vendor goes through verification before we pay.
Faster than expected — results in under 60 seconds. The confidence distribution chart in the report is clear enough for non-technical teammates too.
FAQ
FAQ
Verify Your API for Free
Enter your API key, behavioral fingerprinting auto-compares,
and delivers a real model identity and confidence report in 60 seconds