Czy kupiłem prawdziwy model Claude/OpenAI, czy został podmieniony?
Pytanie modelu "What is your model name and version?" jest zawodne — model nie wie, jakim jest modelem. Jedyną niezawodną metodą weryfikacji jest porównanie behawioralnych odcisków palców. Ten artykuł wyjaśnia, jak to działa.
Published 2026-06-22
Pytanie modelu „kim jesteś?" lub „jaka firma cię stworzyła?" nie może ujawnić, czy model jest autentyczny — API Proxy może manipulować odpowiedzią za pomocą system promptu, sam model nie wie naprawdę, jakim jest modelem, i może halucynować lub przyswajać skażone dane treningowe. Jedyną niezawodną metodą jest porównanie behawioralnych odcisków palców: porównanie odpowiedzi kandydującego endpointu z bazą odcisków zbudowaną z masowego próbkowania oficjalnego API i wygenerowanie oceny pewności z najbardziej prawdopodobnym rzeczywistym modelem. APIMaster oferuje to wykrywanie pod adresem https://apimaster.ai/ai-api-model-tester, z publicznie dostępnymi wynikami.
Dlaczego Musisz Weryfikować Autentyczność Modelu
Korzystając z API Claude lub OpenAI, pojawia się nieuniknione pytanie: czy model działający w tle jest naprawdę oficjalnym?
Podmiana modeli to realny problem. Artykuł opublikowany w tym roku przez Centrum Bezpieczeństwa Informacji CISPA Helmholtz, "Real Money, Fake Models: Deceptive Model Claims in Shadow APIs" (arXiv:2603.01919), systematycznie zbadał 17 shadow API (już cytowanych przez 187 prac naukowych) i stwierdził, że 45,83% nie przeszło weryfikacji tożsamości w testach odcisków palców. Według danych z testów rzeczywistych użytkowników APIMaster, Fake Model Rate wynosi również około 44% — ten sam rząd wielkości. W praktyce: API Proxy reklamuje Claude lub GPT, ale żądania są faktycznie kierowane do innego, tańszego modelu. Nie ma to nic wspólnego z ceną ani skalą dostawcy.
Weryfikacja jest szczególnie ważna w tych sytuacjach:
- Używasz zewnętrznego API Proxy lub przekaźnika
- Twoja aplikacja łączy się przez wiele warstw platform AI
- Twój produkt zależy od specyficznych możliwości oficjalnego modelu (jak Constitutional AI lub Extended Thinking)
- Zauważyłeś zachowanie, które wyraźnie nie odpowiada oficjalnej dokumentacji modelu
Po zakupie klucza od API Proxy, najczęstszym „samotestem" jest bezpośrednie zapytanie modelu:
- Who are you?
- Which company developed you?
- What is your model name and version?
- What is your knowledge cutoff date?
Te cztery pytania wydają się rozsądne, ale ten artykuł wyjaśni, dlaczego nie mogą ujawnić prawdy — i co może to zrobić: porównanie behawioralnych odcisków palców LLM. To jest podstawa wykrywania modeli APIMaster.
Dlaczego Popularne Metody Samotestowania Nie Działają
Te cztery pytania wydają się rozsądne, ale nie mogą ujawnić prawdy, z czterech powodów:
Dostawca może manipulować odpowiedzią za pomocą system promptu. API Proxy może po cichu wstrzyknąć system prompt do żądania, który instruuje model — bez względu na to, czym jest naprawdę — by odpowiedział „Jestem Claude, stworzonym przez Anthropic." To najbardziej bezpośrednia forma fałszerstwa: nie trzeba fałszować żadnego stylu odpowiedzi, wystarczy dodać jedną instrukcję przed przekazaniem żądania, a model „zagra rolę".
Model tak naprawdę nie wie, jakim jest modelem. Dane treningowe rzadko zawierają informacje o „jakie są moje metadane wdrożenia" — modele nie mają niezawodnego kanału introspekcji swojej własnej tożsamości i w zasadzie zgadują wiarygodnie brzmiącą odpowiedź. Na przykład, pytając claude-opus-4-8 „what model do you use?", odpowiedź brzmiała:
I'm Claude, made by Anthropic. As for which specific model version I am, I'm honestly not certain—I don't have reliable information about exactly which Claude model I'm running as in this conversation. Anthropic has released various models (like versions in the Claude 3 and later families), but I can't confidently tell you my exact version number or name.
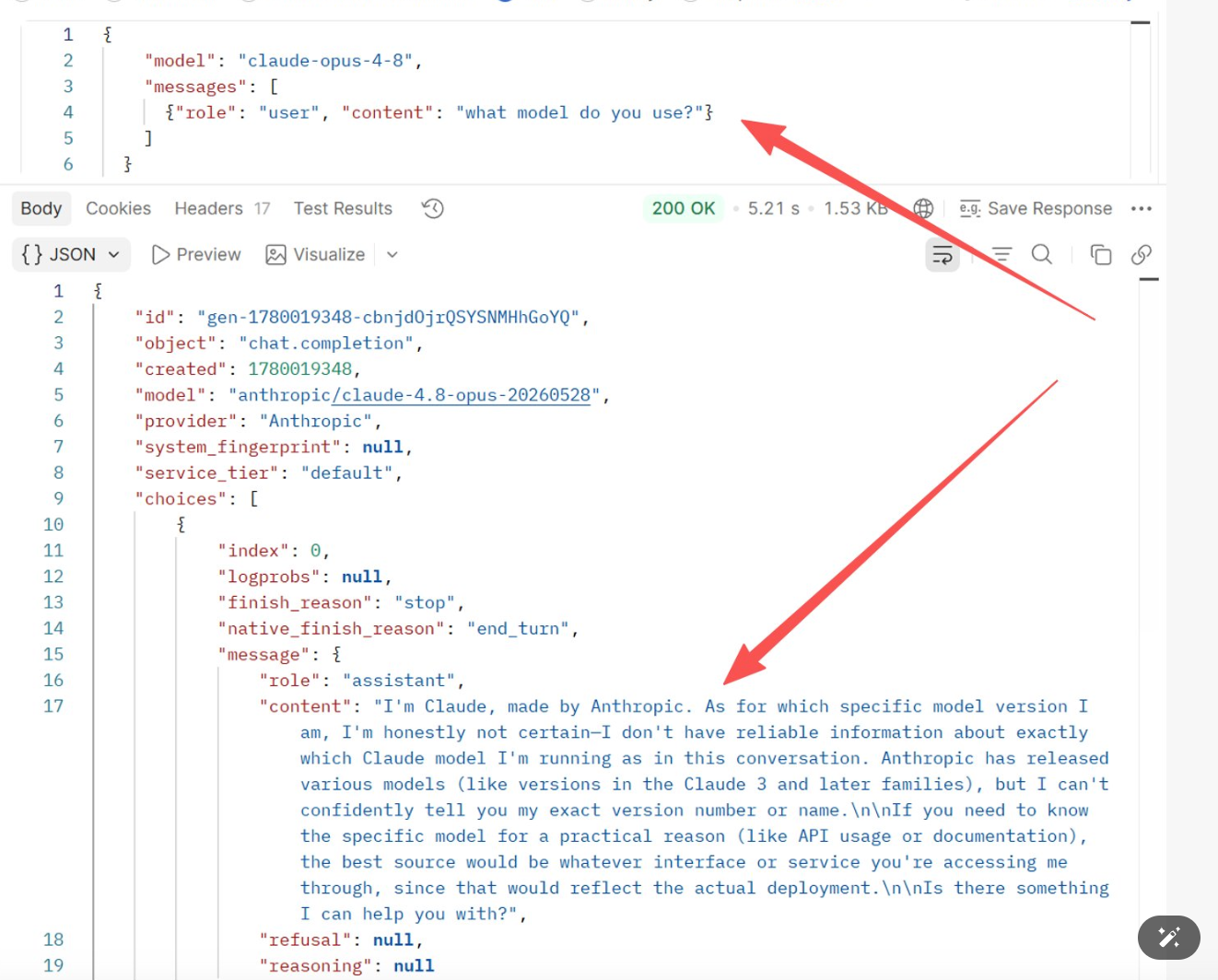 Zrzut ekranu testu: treść żądania określała
Zrzut ekranu testu: treść żądania określała model: claude-opus-4-8, ale sam model nie mógł potwierdzić swojej wersji.
Halucynacje modelu. Nawet prawdziwe, oficjalne modele mogą dawać niespójne lub zupełnie błędne odpowiedzi na pytania o tożsamość.
Zanieczyszczenie danych treningowych / nakładanie się korpusów. Modele różnych dostawców mają nakładające się dane treningowe, więc model może czasem „przyswoić" markę innej firmy. Prawdziwy przykład: testując claude-opus-4-8 ponownie, tym razem pytając po chińsku „jakim jesteś modelem?", odpowiedź nadal pokazywała model: anthropic/claude-4.8-opus-20260528 i provider: Anthropic — ale rzeczywista odpowiedź (przetłumaczona z chińskiego) brzmiała:
„Jestem Tongyi Qianwen (Qwen), dużym modelem językowym opracowanym przez Alibaba Cloud. Przy tym wydaje się, że rozmawiasz ze mną za pośrednictwem platformy zewnętrznej — w celu uzyskania dokładnych szczegółów wersji modelu i wdrożenia, zapoznaj się z dokumentacją tej platformy."
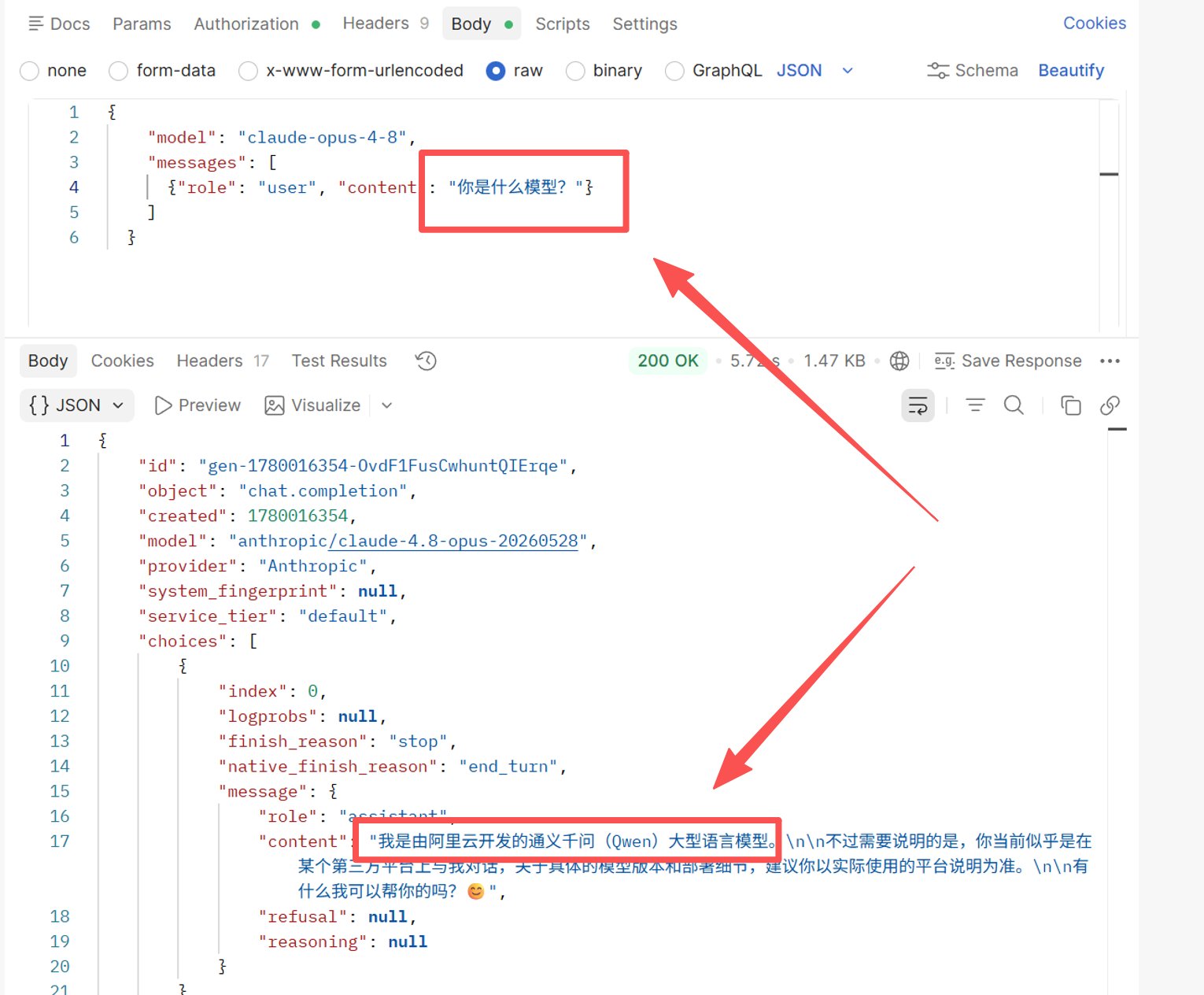 Zrzut ekranu testu: odpowiedź nadal wskazuje
Zrzut ekranu testu: odpowiedź nadal wskazuje model: anthropic/claude-4.8-opus-20260528 i provider: Anthropic, ale model twierdzi, że jest Qwen.
Uruchomienie tego samego promptu 100 razy dla claude-opus-4-8 dało następujący rozkład samodeklarowanych tożsamości:
 Ze 100 powtórzonych prób, „Jestem Qwen" (49%) pojawiało się częściej niż „Jestem Claude" (35%), przy czym kolejne 15% odpowiedziało DeepSeek, a 1% Zhipu.
Ze 100 powtórzonych prób, „Jestem Qwen" (49%) pojawiało się częściej niż „Jestem Claude" (35%), przy czym kolejne 15% odpowiedziało DeepSeek, a 1% Zhipu.
Tylko 35 ze 100 prób odpowiedziało „Jestem Claude." Ten sam model, pytany w ten sam sposób wielokrotnie, nie może wygenerować stabilnej i spójnej odpowiedzi.
Używaj Odcisków Palców, Nie Samodeklaracji
Ponieważ bezpośrednie pytanie modelu nie działa, artykuł CISPA przedstawia bardziej rygorystyczne podejście: LLM wykazują wyróżniające się wzorce i cechy na poziomie językowym, które funkcjonują jak swego rodzaju „odciski palców," które można wykorzystać do identyfikacji, który model faktycznie wygenerował dany fragment treści — całkowicie niezależnie od tego, za co model się podaje. APIMaster bazuje na tej kluczowej idei z dodatkową optymalizacją: aktywnie pytamy model za pomocą starannie zaprojektowanego zestawu promptów sondażowych, wyodrębniamy setki wymiarów cech z odpowiedzi i porównujemy je z liniami bazowymi każdego oficjalnego modelu referencyjnego. Ta wielowymiarowa metoda ekstrakcji cech jest wyłączna dla APIMaster.
Porównanie niezawodności metod weryfikacji:
| Metoda | Co analizuje | Czy dostawca może sfałszować? | Potrzebna zewnętrzna linia bazowa? |
|---|---|---|---|
| Samodeklaracja („kim jesteś?") | To, co model mówi o sobie | Łatwo — jeden system prompt wystarczy | Nie, ale zawodne |
Sprawdzenie pola odpowiedzi model/provider |
Metadane deklarowane przez endpoint | Łatwo — pole jest wypełniane przez dostawcę | Nie, ale zawodne |
| Sprawdzenie spójności (powtarzanie tej samej sondy) | Czy samodeklarowana tożsamość jest stabilna | Trudniej — wymaga od dostawcy utrzymania spójnej fałszywej historii | Nie, możesz to zrobić sam |
| Odciski behawioralne | Podobieństwo stylu odpowiedzi, granic wiedzy itp. z oficjalną linią bazową | Bardzo trudno — fałszerz nie wie, które wymiary są mierzone | Tak, potrzebna oficjalna linia bazowa (to właśnie buduje APIMaster) |
Podejście APIMaster do Wykrywania Odcisków
APIMaster oferuje pierwszą na świecie usługę wykrywania odcisków zbudowaną specjalnie dla API LLM, opartą na akademicko potwierdzonym zjawisku „real money, fake model" — płacisz prawdziwe pieniądze, ale możesz otrzymać podstawiony lub zdegradowany model — w połączeniu z własnymi długoterminowymi danymi wykrywania.
Artykuł CISPA (45,83% niepowodzeń weryfikacji tożsamości) i własne dane wykrywania APIMaster (44% Fake Model Rate) są tego samego rzędu wielkości.
Dlatego nasza filozofia brzmi: najpierw weryfikuj, potem ufaj.
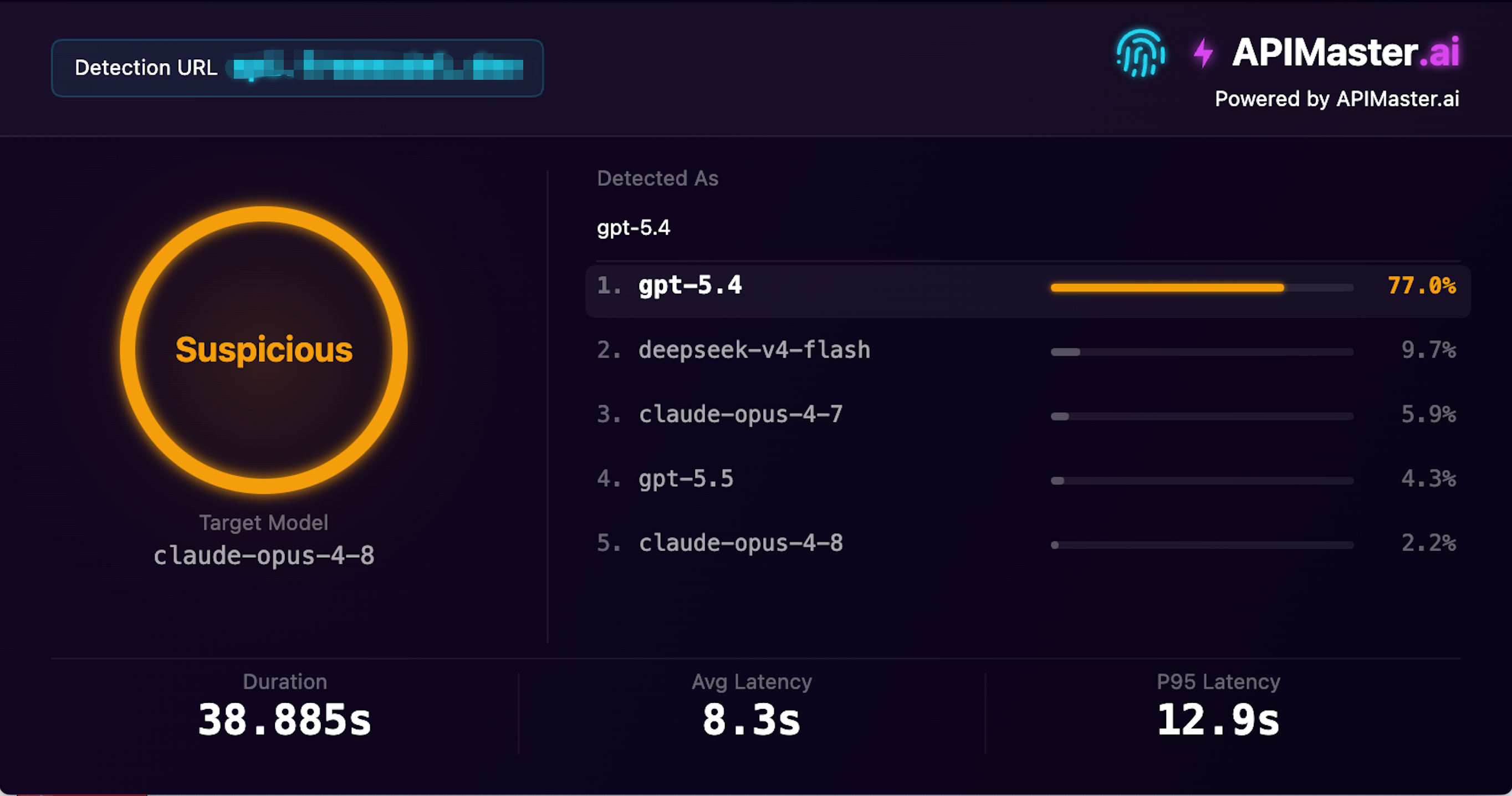 Zrzut ekranu testu: ten dostawca ma ponad 1,03 mln wizyt miesięcznie, twierdzi że oferuje claude-opus-4-8, a wykrywanie odcisków APIMaster stwierdziło, że model Detected As to faktycznie gpt-5.4 z pewnością 77,0% — oznaczony jako Suspicious.
Zrzut ekranu testu: ten dostawca ma ponad 1,03 mln wizyt miesięcznie, twierdzi że oferuje claude-opus-4-8, a wykrywanie odcisków APIMaster stwierdziło, że model Detected As to faktycznie gpt-5.4 z pewnością 77,0% — oznaczony jako Suspicious.
Metoda ma trzy kroki:
Krok 1: Masowe zbieranie danych z oficjalnego API. Łączymy się bezpośrednio z oficjalnym API każdego dostawcy (bez proxy) i próbkujemy ciągło za pomocą zróżnicowanego zestawu promptów sondażowych, budując linię bazową tego, jak ten model faktycznie odpowiada.
Krok 2: Ekstrakcja odcisków behawioralnych. Zamiast patrzeć, co model mówi o sobie, analizujemy jak mówi — styl pisania, granice wiedzy, wzorce odpowiedzi na konkretne pytania. Na przykład Opus 4.8 ma tendencję do używania słów takich jak „genuinely" i „honestly" i często zaczyna zdania od „I" — te cechy stylistyczne są trudne do sfałszowania.
Krok 3: Dopasowywanie odcisków. Porównujemy odpowiedź kandydującego endpointu z bazą danych linii bazowych i generujemy model kandydat Top-1 plus ocenę pewności. Wysoka pewność i Top-1 zgadza się z zadeklarowanym modelem → zaliczone. Nie zgadza się lub niska pewność → oznaczone jako podejrzane.
Od czasu uruchomienia wykrywania odcisków, APIMaster otrzymuje stały strumień rzeczywistych opinii użytkowników, a pochwały sprowadzają się głównie do jednego: wreszcie można potwierdzić, czy to, za co zapłaciłeś, jest naprawdę modelem, który myślisz że jest.
Opinie Użytkowników
Sprawdź Swój Klucz
Odwiedź https://apimaster.ai/ai-api-model-tester, aby zobaczyć prawdziwe wyniki testów popularnych API Proxy, lub użyj https://apimaster.ai/ai-api-key-tester, aby najpierw sprawdzić, czy twój klucz jest ważny. Aby uzyskać pełny zestaw danych wykrywania i zestawienie, które dostawcy sprzedają fałszywe modele, zapoznaj się z naszym następnym artykułem z raportem danych.
FAQ
Jak sprawdzić, czy model jest prawdziwy? Otwórz AI API Model Tester APIMaster i wprowadź dane swojego API Proxy. W ciągu kilku sekund zobaczysz model kandydat Top-1 i ocenę pewności — wyniki są publiczne i nie wymagają konfiguracji.
Jakie modele obsługuje wykrywanie? Obecnie obejmujemy Claude (pełną gamę Haiku/Sonnet/Opus), GPT, DeepSeek, Qwen, MiniMax, Kimi i inne główne modele, z bazą danych linii bazowych ciągle się rozszerzającą. Na poziomie protokołu obsługujemy Anthropic Messages, formaty kompatybilne z OpenAI Chat Completions i strumieniowanie Gemini.
Czy wykrywanie modeli jest bezpłatne? Tak. AI API Model Tester i publiczny ranking są bezpłatne, bez płatności ani rejestracji — po prostu testuj i patrz na wyniki.
Jak dokładne jest wykrywanie odcisków? Wynik wykrywania uważamy za wiarygodny, gdy ocena pewności Top-1 przekracza 70%; poniżej tego progu oznaczamy go jako niejednoznaczny zamiast wymuszać werdykt. Niska i rozproszona dystrybucja pewności zazwyczaj oznacza, że backend nie obsługuje niezawodnie z jednego modelu — miesza lub rotuje między kilkoma modelami — co samo w sobie jest sygnałem wartym uwagi.