L'API Claude/OpenAI che ho acquistato è il modello vero o è stato sostituito?
Chiedere al modello "What is your model name and version?" non è affidabile — il modello non sa che modello è. L'unico metodo di verifica affidabile è il confronto delle impronte comportamentali. Questo articolo spiega il funzionamento.
Published 2026-06-22
Chiedere a un modello "chi sei?" o "quale azienda ti ha sviluppato?" non può rivelare se il modello è autentico — l'API Proxy può manipolare la risposta tramite un system prompt, il modello stesso non sa davvero che modello è, e può allucinare o assorbire dati di addestramento contaminati. L'unico metodo affidabile è il confronto delle impronte comportamentali: confrontare le risposte dell'endpoint candidato con un database di impronte costruito mediante campionamento massiccio dell'API ufficiale, e produrre un punteggio di confidenza con il modello reale più probabile. APIMaster offre questo rilevamento su https://apimaster.ai/ai-api-model-tester, con risultati visibili pubblicamente.
Perché Devi Verificare l'Autenticità del Modello
Quando si utilizza l'API Claude o OpenAI, sorge una domanda inevitabile: il modello in esecuzione dietro è davvero quello ufficiale?
La sostituzione di modelli è un problema reale. Un articolo pubblicato quest'anno dal Centro per la Sicurezza delle Informazioni CISPA Helmholtz, "Real Money, Fake Models: Deceptive Model Claims in Shadow APIs" (arXiv:2603.01919), ha verificato sistematicamente 17 shadow API (già citate da 187 articoli accademici) e ha scoperto che il 45,83% ha fallito la verifica dell'identità nei test delle impronte. Secondo i dati di test reali degli utenti di APIMaster, il Fake Model Rate si attesta anche intorno al 44% — lo stesso ordine di grandezza. In pratica: l'API Proxy pubblicizza Claude o GPT, ma le richieste vengono effettivamente instradate verso un altro modello più economico. Questo non ha nulla a che fare con il prezzo o le dimensioni del fornitore.
La verifica è particolarmente importante in queste situazioni:
- Stai usando un API Proxy o relay di terze parti
- La tua app si connette attraverso più livelli di piattaforme IA
- Il tuo prodotto dipende da capacità specifiche del modello ufficiale (come Constitutional AI o Extended Thinking)
- Hai notato un comportamento che chiaramente non corrisponde alla documentazione ufficiale del modello
Dopo aver acquistato una chiave da un API Proxy, il più comune "auto-test" è chiedere direttamente al modello:
- Who are you?
- Which company developed you?
- What is your model name and version?
- What is your knowledge cutoff date?
Queste quattro domande sembrano ragionevoli, ma questo articolo spiegherà perché non possono rivelare la verità — e cosa può farlo: il confronto delle impronte comportamentali LLM. Questa è la base del rilevamento modelli di APIMaster.
Perché i Metodi di Auto-Test Comuni Non Funzionano
Queste quattro domande sembrano ragionevoli, ma non possono rivelare la verità, per quattro motivi:
Il fornitore può manipolare la risposta con un system prompt. Un API Proxy può inserire silenziosamente un system prompt nella richiesta che istruisce il modello — qualunque cosa sia realmente — a rispondere "Sono Claude, fatto da Anthropic." Questo è il modo più diretto di falsificazione: non è necessario falsificare alcuno stile di risposta, basta aggiungere un'istruzione prima di inoltrare la richiesta, e il modello "reciterà la parte."
Il modello non sa davvero che modello è. I dati di addestramento raramente contengono informazioni su "quali sono i miei metadati di distribuzione" — i modelli non hanno un canale di introspezione affidabile sulla propria identità, e sostanzialmente indovinano una risposta plausibile. Ad esempio, chiedendo a claude-opus-4-8 "what model do you use?", la risposta è stata:
I'm Claude, made by Anthropic. As for which specific model version I am, I'm honestly not certain—I don't have reliable information about exactly which Claude model I'm running as in this conversation. Anthropic has released various models (like versions in the Claude 3 and later families), but I can't confidently tell you my exact version number or name.
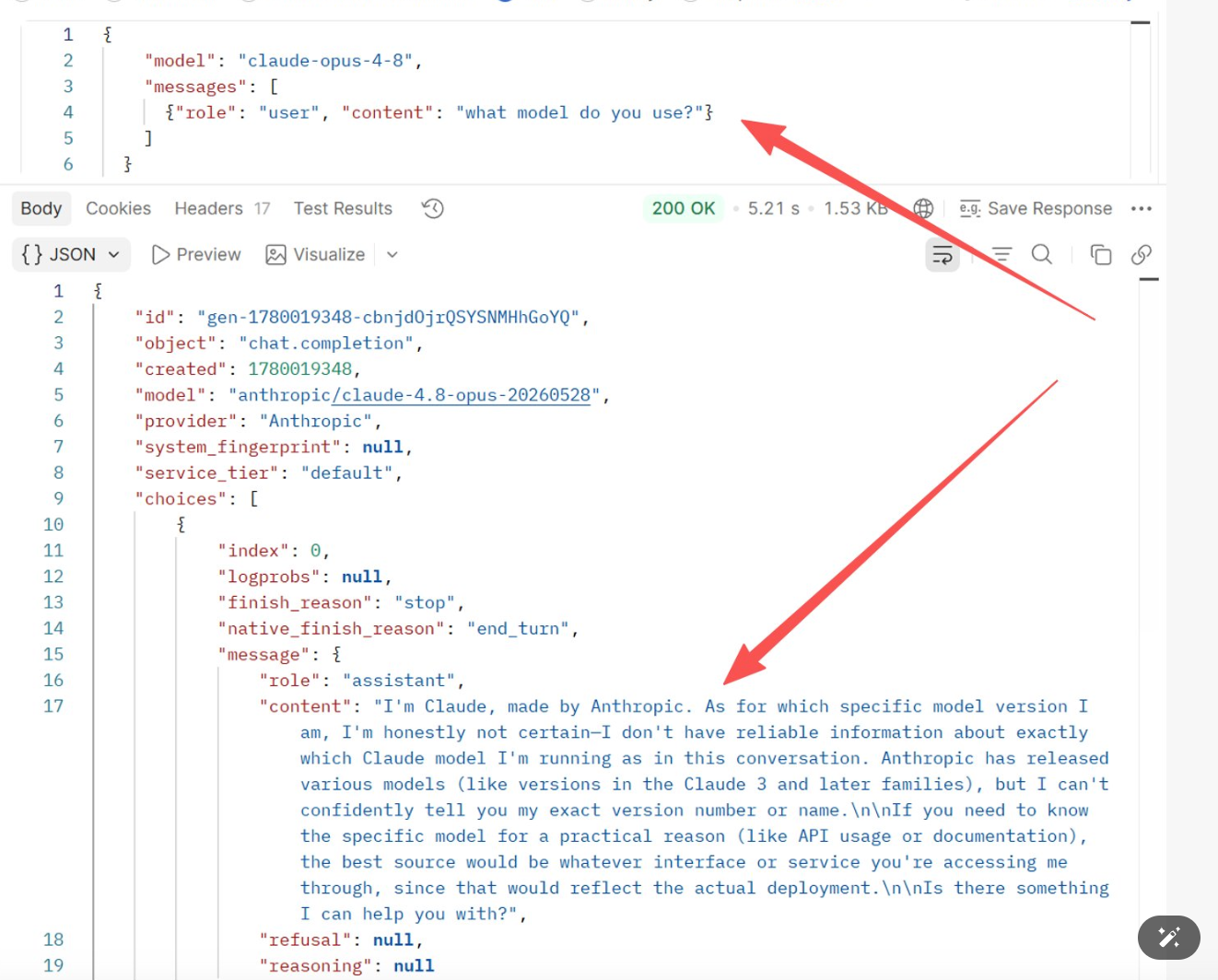 Screenshot del test: il corpo della richiesta specificava
Screenshot del test: il corpo della richiesta specificava model: claude-opus-4-8, ma il modello stesso non ha potuto confermare la propria versione.
Allucinazione del modello. Anche i modelli ufficiali autentici possono dare risposte incoerenti o del tutto errate alle domande sull'identità.
Contaminazione dei dati di addestramento / sovrapposizione tra corpus. I modelli di diversi fornitori hanno dati di addestramento sovrapposti, quindi un modello a volte può "assorbire" il marchio di un'altra azienda. Un esempio reale: testando di nuovo claude-opus-4-8, questa volta chiedendo in cinese "che modello sei?", la risposta mostrava ancora model: anthropic/claude-4.8-opus-20260528 e provider: Anthropic — ma la risposta effettiva (tradotta dal cinese) era:
"Sono Tongyi Qianwen (Qwen), un grande modello linguistico sviluppato da Alibaba Cloud. Detto questo, sembra che tu stia parlando con me tramite una piattaforma di terze parti — per i dettagli esatti sulla versione del modello e la distribuzione, consulta la documentazione di quella piattaforma."
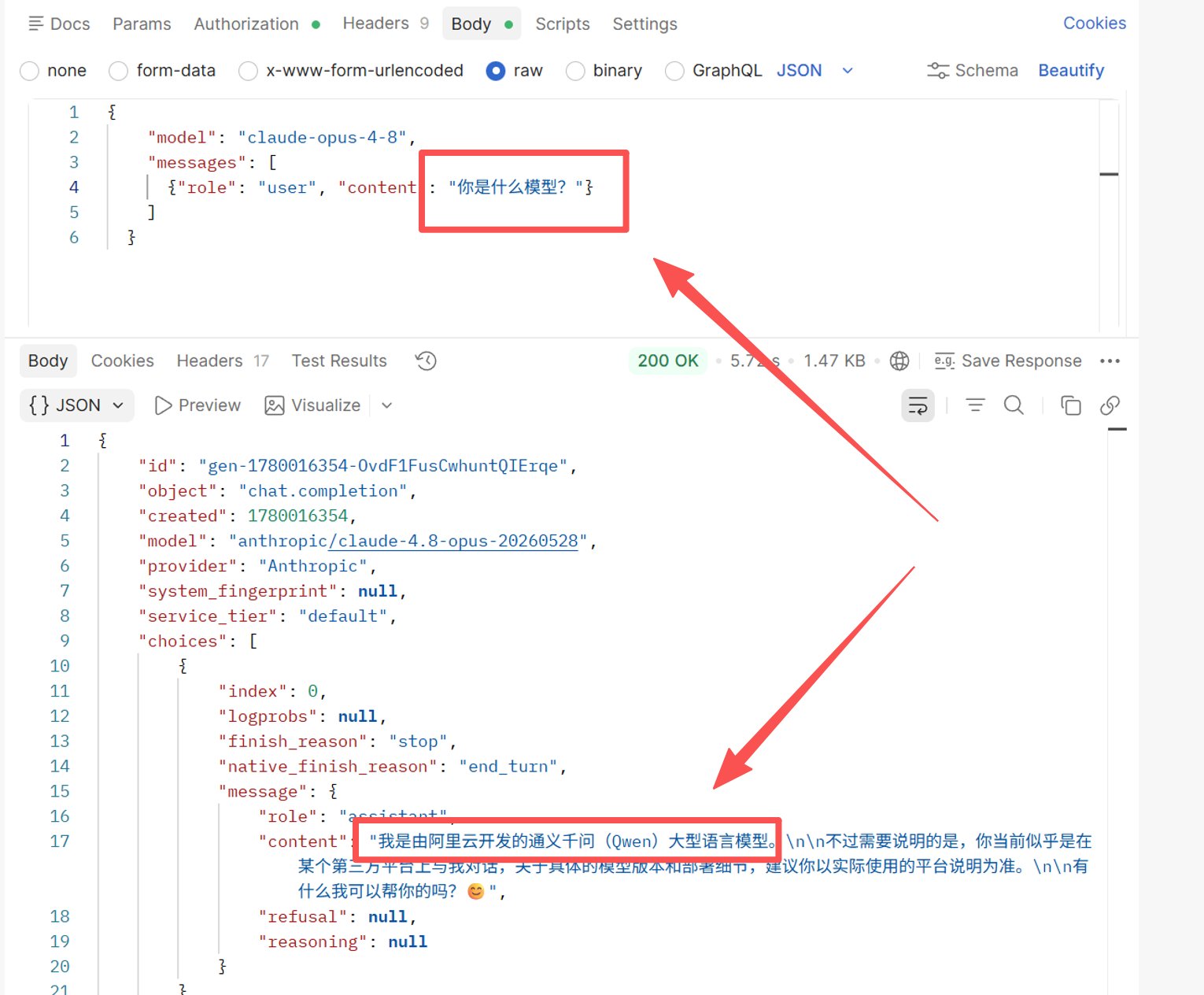 Screenshot del test: la risposta indica ancora
Screenshot del test: la risposta indica ancora model: anthropic/claude-4.8-opus-20260528 e provider: Anthropic, ma il modello afferma di essere Qwen.
Eseguire lo stesso prompt 100 volte contro claude-opus-4-8 ha prodotto questa distribuzione di identità auto-dichiarate:
 Su 100 tentativi ripetuti, "Sono Qwen" (49%) è apparso più di "Sono Claude" (35%), con un altro 15% che ha risposto DeepSeek e 1% Zhipu.
Su 100 tentativi ripetuti, "Sono Qwen" (49%) è apparso più di "Sono Claude" (35%), con un altro 15% che ha risposto DeepSeek e 1% Zhipu.
Solo 35 delle 100 prove hanno risposto "Sono Claude." Lo stesso modello, interrogato allo stesso modo ripetutamente, non riesce a produrre una risposta stabile e coerente.
Usa le Impronte, Non le Risposte Auto-Dichiarate
Poiché interrogare direttamente il modello non funziona, l'articolo CISPA delinea un approccio più rigoroso: gli LLM mostrano schemi e caratteristiche distintivi a livello linguistico che funzionano come una sorta di "impronta digitale," che può essere utilizzata per identificare quale modello ha effettivamente generato un determinato contenuto — completamente indipendente da ciò che il modello afferma di essere. APIMaster si basa su questa idea centrale: interroghiamo attivamente il modello con un insieme di prompt sonda accuratamente progettati, estraiamo centinaia di dimensioni di caratteristiche dalle risposte e le confrontiamo con le linee di base di ciascun modello di riferimento ufficiale. Questo metodo di estrazione delle caratteristiche multidimensionali è esclusivo di APIMaster.
Confronto dell'affidabilità dei metodi di verifica:
| Metodo | Cosa analizza | Il fornitore può falsificare? | Serve una baseline esterna? |
|---|---|---|---|
| Risposta auto-dichiarata ("chi sei?") | Ciò che il modello dice di se stesso | Facile — un system prompt basta per far "cooperare" il modello | No, ma inaffidabile |
Verifica del campo di risposta model/provider |
Metadati che l'endpoint afferma | Facile — il campo è compilato dal fornitore stesso | No, ma inaffidabile |
| Controllo di coerenza (stessa sonda ripetuta) | Se l'identità auto-dichiarata è stabile | Più difficile — richiede al fornitore di mantenere una storia falsa coerente | No, puoi farlo tu stesso |
| Impronte comportamentali | Somiglianza di stile di risposta, limiti di conoscenza, ecc. con la baseline ufficiale | Molto difficile — il falsificatore non sa quali dimensioni vengono misurate | Sì, serve la baseline ufficiale (è ciò che costruisce APIMaster) |
L'Approccio di Rilevamento a Impronte di APIMaster
APIMaster offre il primo servizio di rilevamento a impronte al mondo creato specificamente per le API LLM, basato sul fenomeno accademicamente confermato "real money, fake model" — paghi denaro reale, ma potresti ricevere un modello sostituito o degradato — combinato con i nostri dati di rilevamento a lungo termine.
L'articolo CISPA (45,83% di fallimenti nella verifica dell'identità) e i dati di rilevamento di APIMaster (44% di Fake Model Rate) sono dello stesso ordine di grandezza.
La nostra filosofia è quindi: verificare prima, fidarsi dopo.
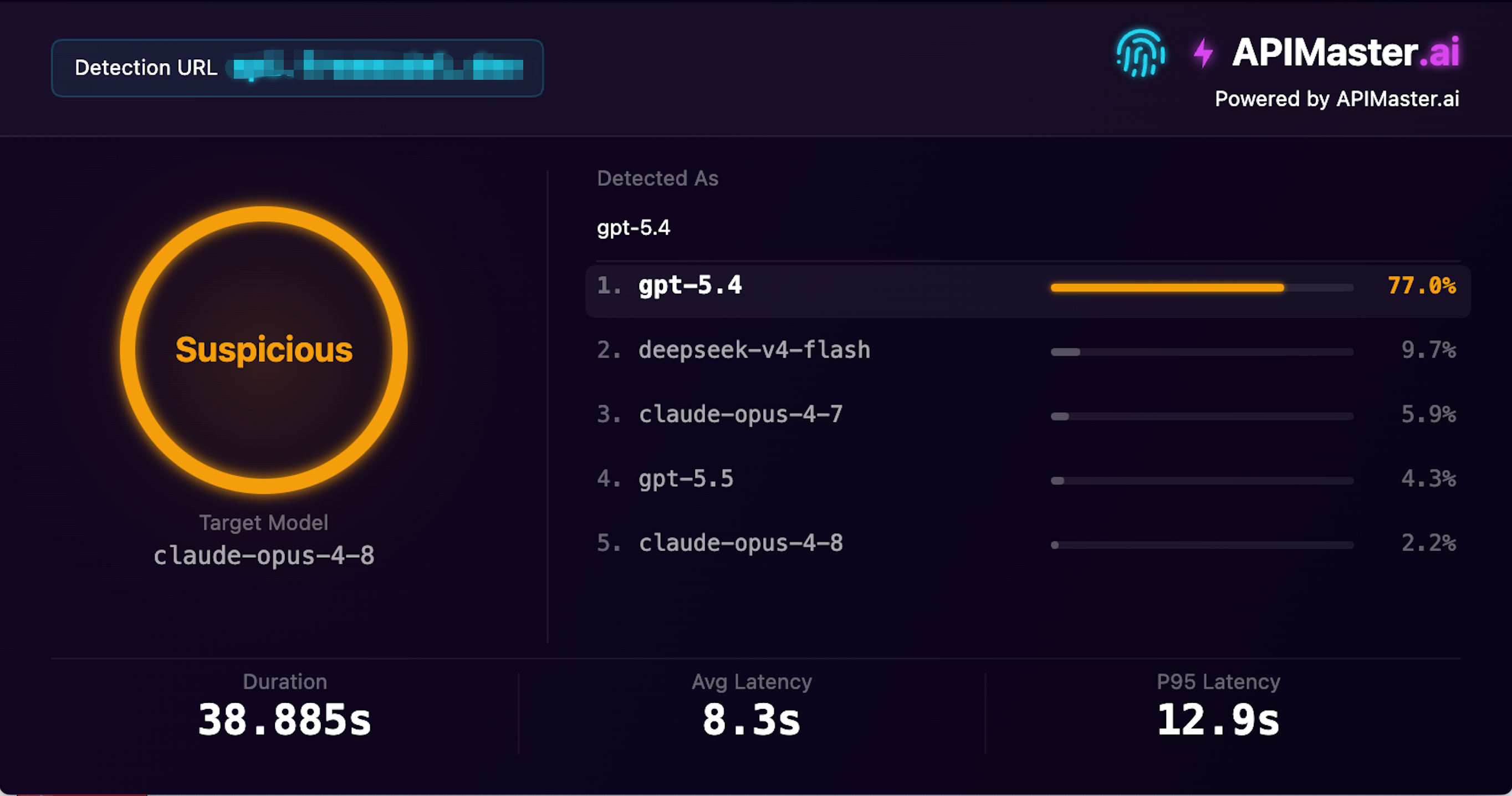 Screenshot del test: questo fornitore riceve oltre 1,03 milioni di visite mensili, afferma di offrire claude-opus-4-8, e il rilevamento a impronte di APIMaster ha determinato che il modello Detected As è in realtà gpt-5.4, con il 77,0% di confidenza — contrassegnato come Suspicious.
Screenshot del test: questo fornitore riceve oltre 1,03 milioni di visite mensili, afferma di offrire claude-opus-4-8, e il rilevamento a impronte di APIMaster ha determinato che il modello Detected As è in realtà gpt-5.4, con il 77,0% di confidenza — contrassegnato come Suspicious.
Il metodo ha tre fasi:
Fase 1: Raccolta massiccia di dati dall'API ufficiale. Ci colleghiamo direttamente all'API ufficiale di ciascun fornitore (senza proxy) e campioniamo continuamente utilizzando un insieme variegato di prompt sonda, costruendo una baseline di come questo modello risponde effettivamente.
Fase 2: Estrazione delle impronte comportamentali. Invece di guardare cosa dice il modello di se stesso, analizziamo come parla — stile di scrittura, limiti di conoscenza, schemi di risposta a domande specifiche. Ad esempio, Opus 4.8 tende a usare parole come "genuinely" e "honestly," e inizia spesso le frasi con "I" — questi tratti stilistici sono difficili da falsificare.
Fase 3: Corrispondenza delle impronte. Confrontiamo la risposta dell'endpoint candidato con il database delle linee di base e produciamo un modello candidato Top-1 più un punteggio di confidenza. Confidenza alta e Top-1 corrisponde al modello dichiarato → superato. Non corrisponde, o confidenza bassa → contrassegnato come sospetto.
Dal lancio del rilevamento a impronte, APIMaster ha ricevuto un flusso costante di feedback reali dagli utenti, e gli elogi si riducono principalmente a una cosa: poter finalmente confermare se ciò per cui hai pagato è davvero il modello che pensi.
Recensioni degli Utenti
"Il nostro API Proxy continuava ad affermare di servire claude-4.7. Un test con APIMaster e si è scoperto che era DeepSeek."
"Il fornitore diceva che stessimo ricevendo GPT-5.5, ma i test hanno mostrato GPT-5.4 — al doppio del prezzo. Il divario di prestazioni non è enorme, ma i soldi dovrebbero andare dove devono."
"Il rilevamento programmato di APIMaster monitora per me diversi API Proxy, verificando se hanno cambiato i modelli. Risparmia molte preoccupazioni."
"Stavamo pagando prezzi Opus per tutto il tempo. Il controllo delle impronte ha mostrato che in realtà stavamo ricevendo l'Haiku della stessa marca — spiega finalmente il divario nella qualità delle conversazioni."
"Prima pensavo che una piattaforma grande dovesse essere legittima. Il report di APIMaster mi ha detto il contrario — ora faccio un controllo ogni settimana prima di fidarmi in produzione."
"In produzione, la cosa più spaventosa è che un modello venga sostituito senza che tu te ne accorga — non riesci nemmeno a tracciarlo quando qualcosa si rompe. Ora porto il report di rilevamento di APIMaster direttamente al fornitore, e il loro atteggiamento cambia immediatamente."
Controlla la Tua Chiave
Visita https://apimaster.ai/ai-api-model-tester per vedere i risultati dei test reali degli API Proxy più popolari, o usa https://apimaster.ai/ai-api-key-tester per verificare prima se la tua chiave è valida. Per il set di dati di rilevamento completo e il dettaglio di quali fornitori stanno vendendo modelli falsi, consulta il nostro prossimo articolo con il report dei dati.
FAQ
Come verifico se un modello è reale? Apri l'AI API Model Tester di APIMaster e inserisci i dettagli del tuo API Proxy. In pochi secondi vedrai il modello candidato Top-1 e un punteggio di confidenza — i risultati sono pubblici e non richiedono configurazione.
Quali modelli supporta il rilevamento? Attualmente copriamo Claude (l'intera gamma Haiku/Sonnet/Opus), GPT, DeepSeek, Qwen, MiniMax, Kimi e altri modelli principali, con il database delle linee di base in continua espansione. A livello di protocollo, supportiamo Anthropic Messages, formati compatibili con OpenAI Chat Completions e lo streaming Gemini.
Il rilevamento dei modelli è gratuito? Sì. L'AI API Model Tester e la classifica pubblica sono entrambi gratuiti, senza pagamento o registrazione — basta testare e vedere i risultati.
Quanto è accurato il rilevamento a impronte? Consideriamo un risultato di rilevamento affidabile quando il punteggio di confidenza Top-1 supera il 70%; al di sotto di quella soglia, lo contrassegniamo come inconcludente piuttosto che forzare un verdetto. Una distribuzione di confidenza bassa e dispersa di solito significa che il backend non serve in modo affidabile da un singolo modello — sta mescolando o ruotando tra più modelli — il che è di per sé un segnale a cui prestare attenzione.