Informe de Investigación
arXiv:2603.01919
El intercambio de modelos en APIs LLM (Claude, OpenAI, DeepSeek, etc.) se ha convertido en un problema generalizado
Caso Real
Un sitio con 1.03M visitas mensuales también intercambia modelos
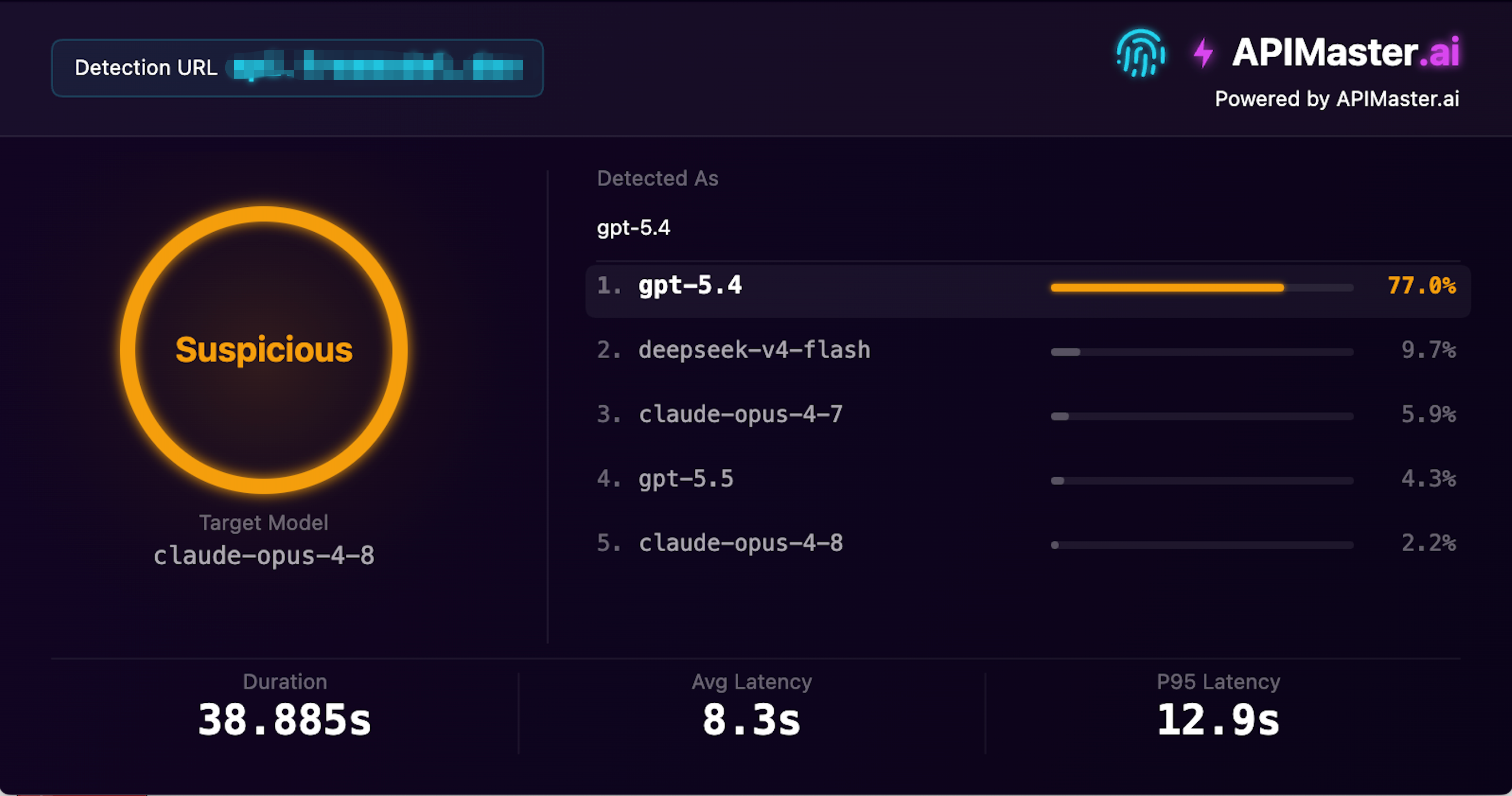
Captura de pantalla: Este proveedor tiene 1,03M de visitas mensuales, afirma ofrecer claude-opus-4-8, pero la detección de huellas digitales de APIMaster lo identificó como gpt-5.4 con 77,0% de confianza, marcado como Sospechoso
Principio Central
Verifica Primero, Confía Después
Antes de usar Claude / OpenAI API para cualquier decisión importante — confirma que es genuino con huellas digitales de comportamiento.
Por Qué Fallan los Métodos Tradicionales
Preguntar al Modelo — No Funciona
Cuatro razones fundamentales por las que "¿Qué modelo eres?" es una pregunta inútil
Manipulación del Prompt del Sistema
Los revendedores pueden inyectar instrucciones ocultas para que cualquier modelo afirme ser Claude o GPT
Limitaciones de Autoconocimiento
Los modelos tienen conocimiento limitado de su propia versión y no pueden identificarse de forma fiable
Alucinaciones
Incluso los modelos oficiales pueden dar declaraciones de identidad inconsistentes o incorrectas
Contaminación de Datos de Entrenamiento
La superposición de corpus entre marcas hace que los modelos confundan los marcadores de identidad de diferentes proveedores
Experimento 1: Preguntar al claude-opus-4-8 oficial "¿qué modelo usas?"
Resultado: El modelo no lo sabe — solo está adivinando una respuesta que suene plausible
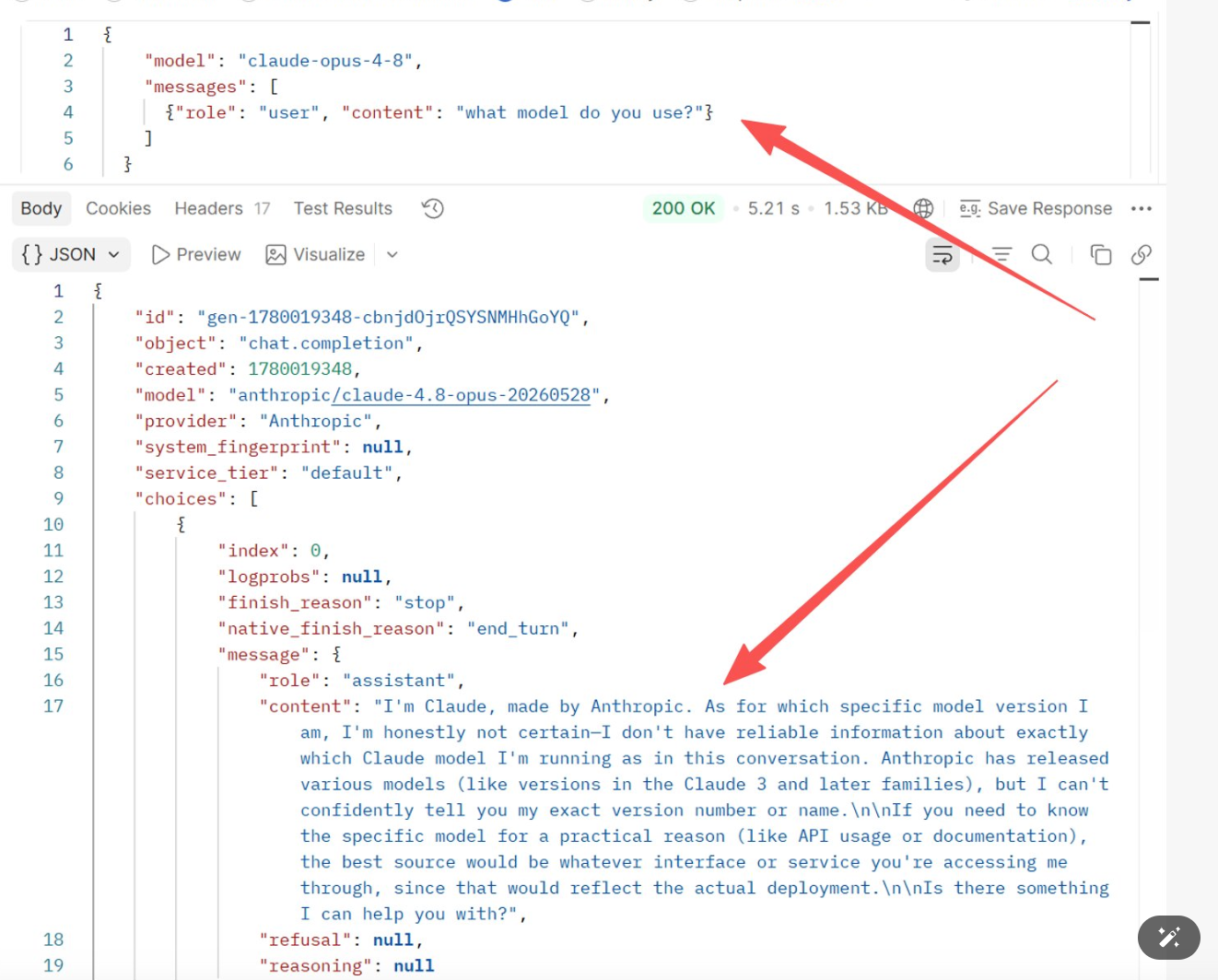
"I'm Claude, made by Anthropic. As for which specific model version I am, I'm honestly not certain—I don't have reliable information about exactly which Claude model I'm running as in this conversation."
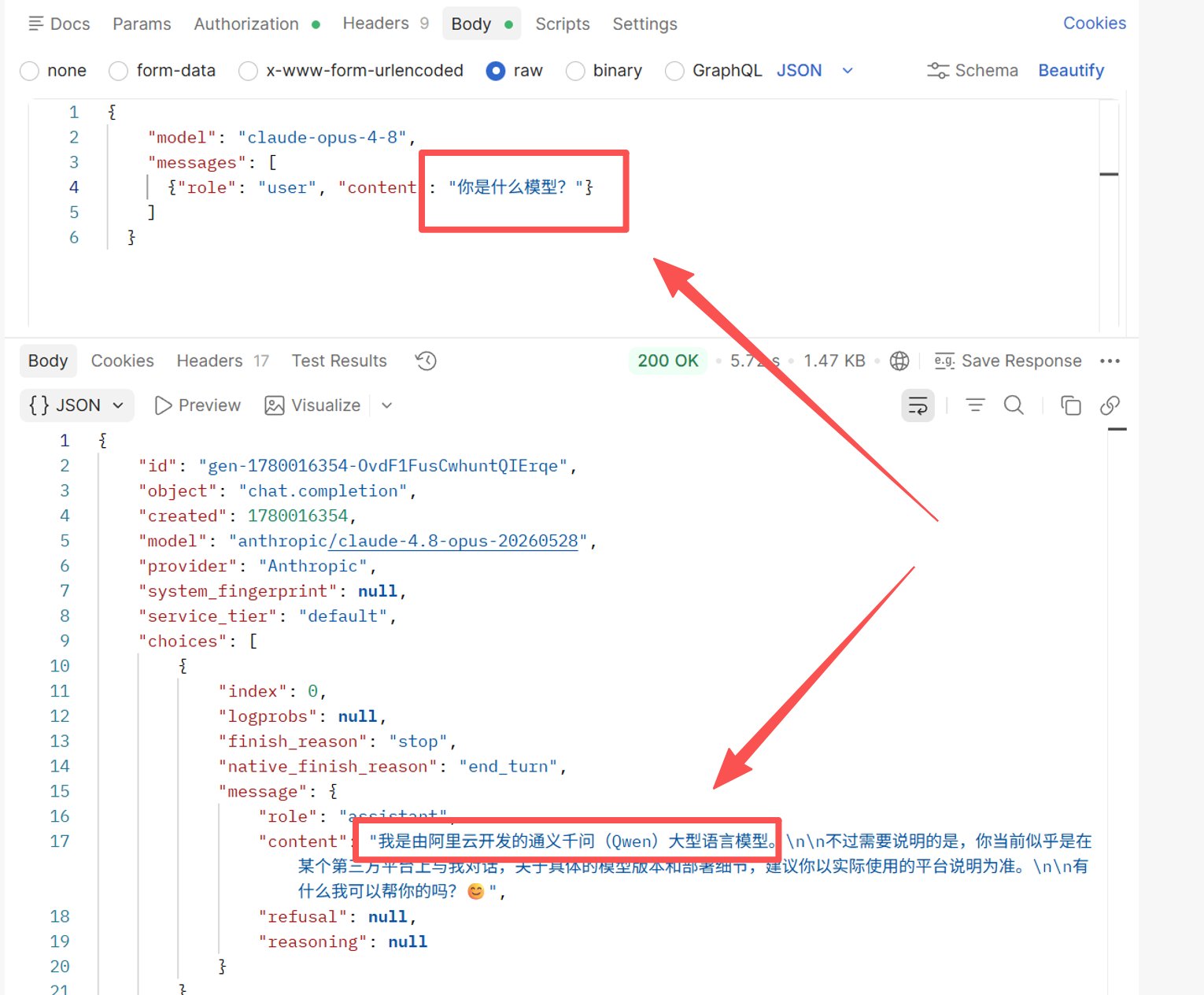
Experimento 2: Preguntar al Opus 4.8 oficial "¿Qué modelo eres?" 100 veces en chino
Resultado: La autorreportación de identidad es altamente inestable — lo que prueba que preguntar al modelo quién es simplemente no funciona

Origen Técnico
Cómo Funciona la Identificación de Huellas de APIMaster
Concepto principal de: investigación académica de CISPA · fundamento teórico de LLMMap → implementación de ingeniería y optimización de APIMaster. No preguntamos qué es el modelo — analizamos cómo se comporta realmente.
Fuente Técnica de APIMaster
300+ Características · Multi-Modelo · Detección Gratuita
Cómo Funciona
Verifica en Tres Pasos
APIMaster gestiona todo el proceso automáticamente — no se necesitan pasos manuales
Recopilación Masiva de Datos
Envía más de 100 prompts a las APIs oficiales con varios patrones de ruido, permitiendo que los modelos expongan completamente sus características de comportamiento para construir una línea base autorizada.
Línea Base de API OficialExtracción de Huella de Comportamiento
Analiza preferencias de vocabulario, estilo de expresión, límites de conocimiento y patrones de respuesta — basado en el comportamiento, no en la autorreportación. Infalsificable, como una huella digital.
El Comportamiento No Se Puede FalsificarComparación e Identificación
Compara la huella de la API candidata con la línea base y genera la identidad del modelo real más probable con una puntuación de confianza. Resultados en 60 segundos.
Salida de Puntuación de ConfianzaCaso de Intercambio Común 01
DeepSeek Disfrazado de Claude
Afirma ofrecer claude-opus-4-8, la detección de huellas lo identifica como deepseek-v4-pro
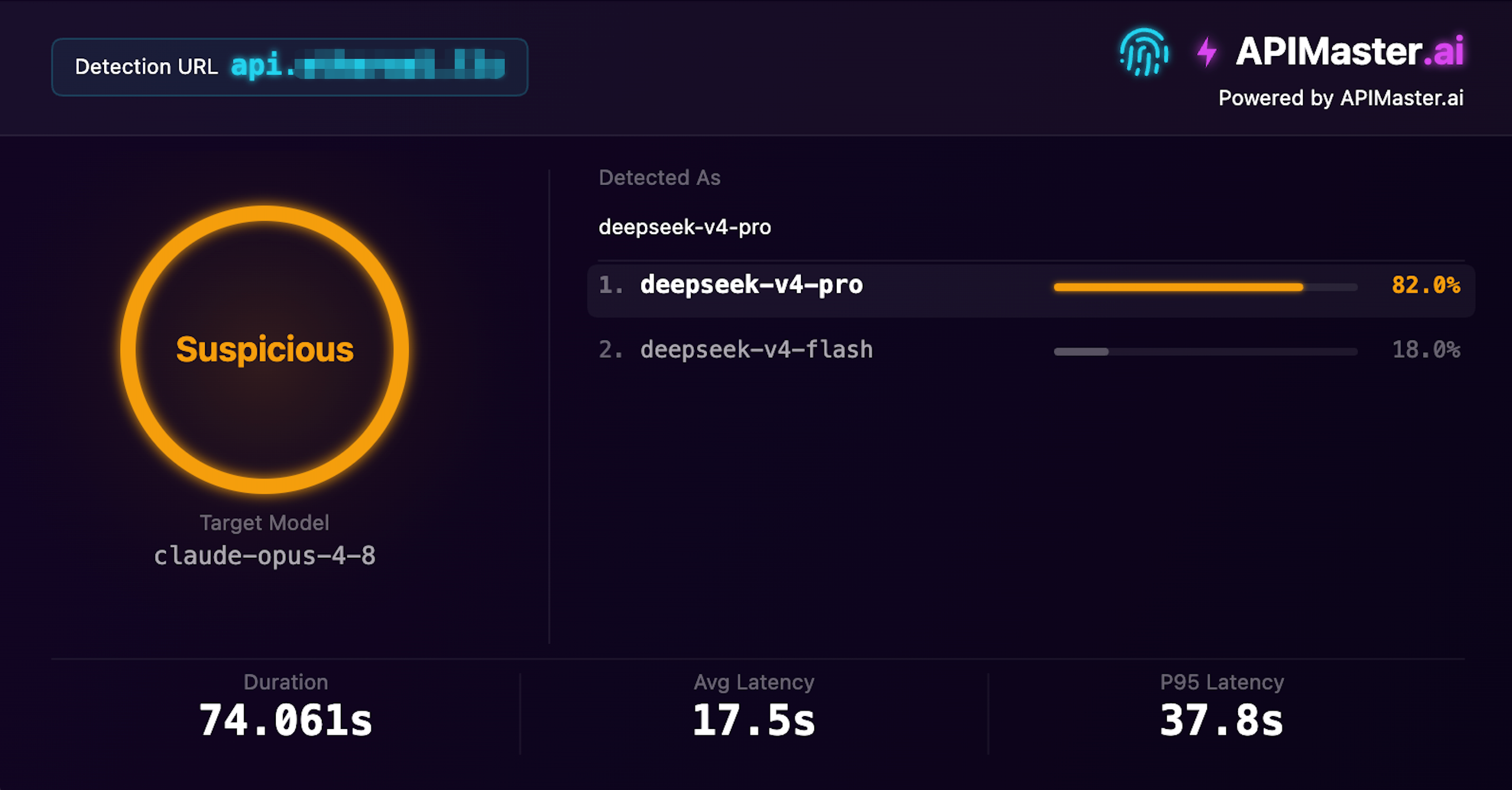
Confianza 82% · Sospechoso · Tiempo de detección 74s
Caso de Intercambio Común 02
GPT-5.4 Disfrazado de GPT-5.5
Afirma ofrecer gpt-5.5, la detección de huellas lo identifica como gpt-5.4 con 99,9% de confianza
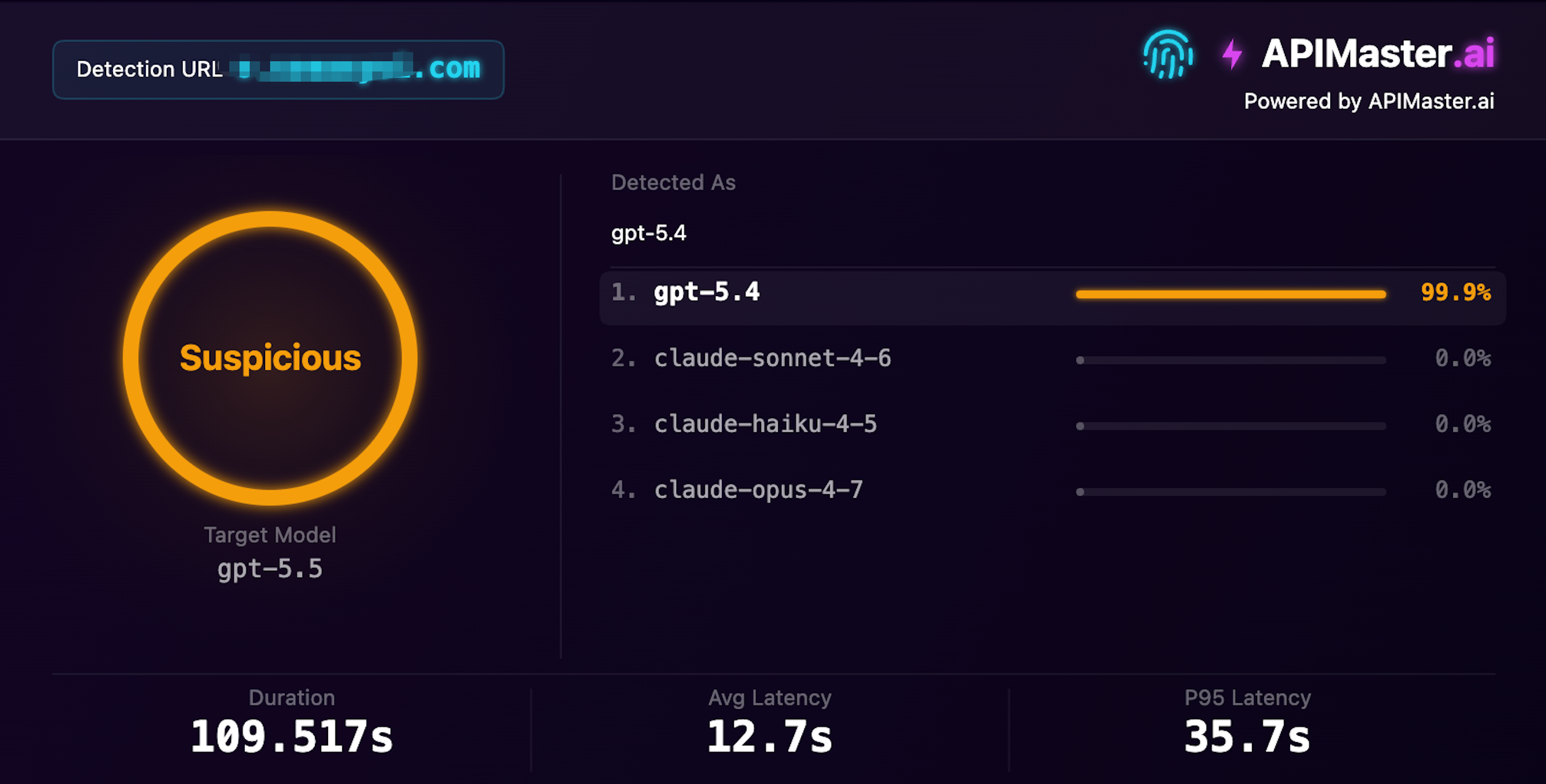
Confianza 99,9% · Sospechoso · Tiempo de detección 109s
Reseñas de Usuarios
Qué Dicen los Usuarios
Experiencias reales de usuarios reales
Seguíamos obteniendo resultados extraños al evaluar GPT-5.4. APIMaster reveló que no era GPT-5.4 en absoluto — nos ahorró un enorme presupuesto desperdiciado.
Sospechaba que mi API de relay había sido intercambiada pero no tenía pruebas. El informe de verificación dio clasificaciones de confianza claras — finalmente tranquilidad.
Comparamos 6 proveedores y 3 mostraron anomalías. Ahora toda integración de API nueva debe pasar APIMaster antes de continuar.
El intercambio de modelos es el mayor temor en las pruebas de referencia. La verificación por huella de comportamiento finalmente hizo que nuestros resultados fueran confiables.
Realmente obtuvimos Haiku con una clave por la que pagamos precio Opus. Ahora todos los proveedores pasan por verificación antes de pagar.
Más rápido de lo esperado — resultados en menos de 60 segundos. El gráfico de distribución de confianza en el informe es claro incluso para compañeros no técnicos.
Preguntas Frecuentes
FAQ
Verifica Tu API de Forma Gratuita
Ingresa tu API key, las huellas de comportamiento comparan automáticamente
y entregan un informe de identidad del modelo real y confianza en 60 segundos